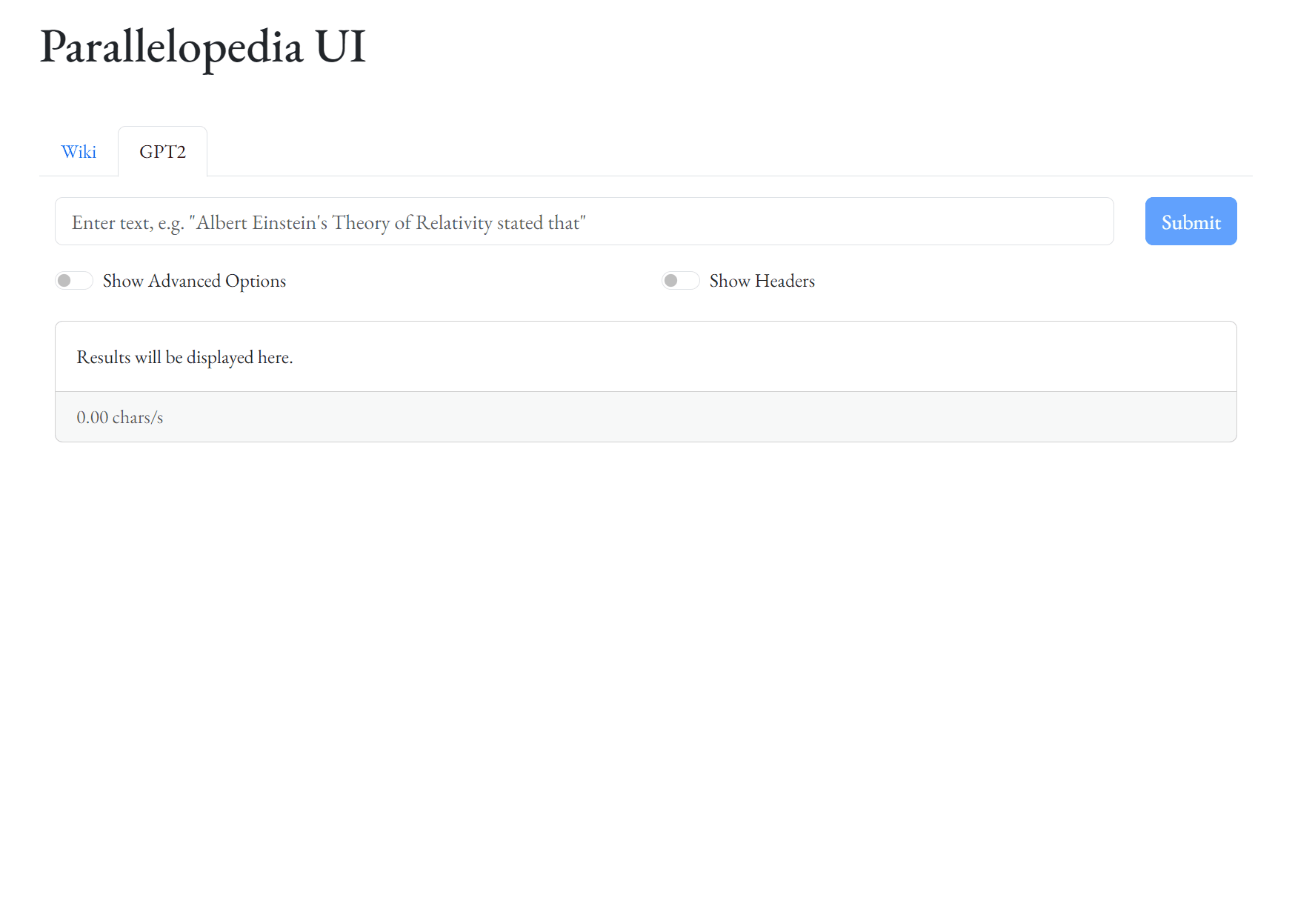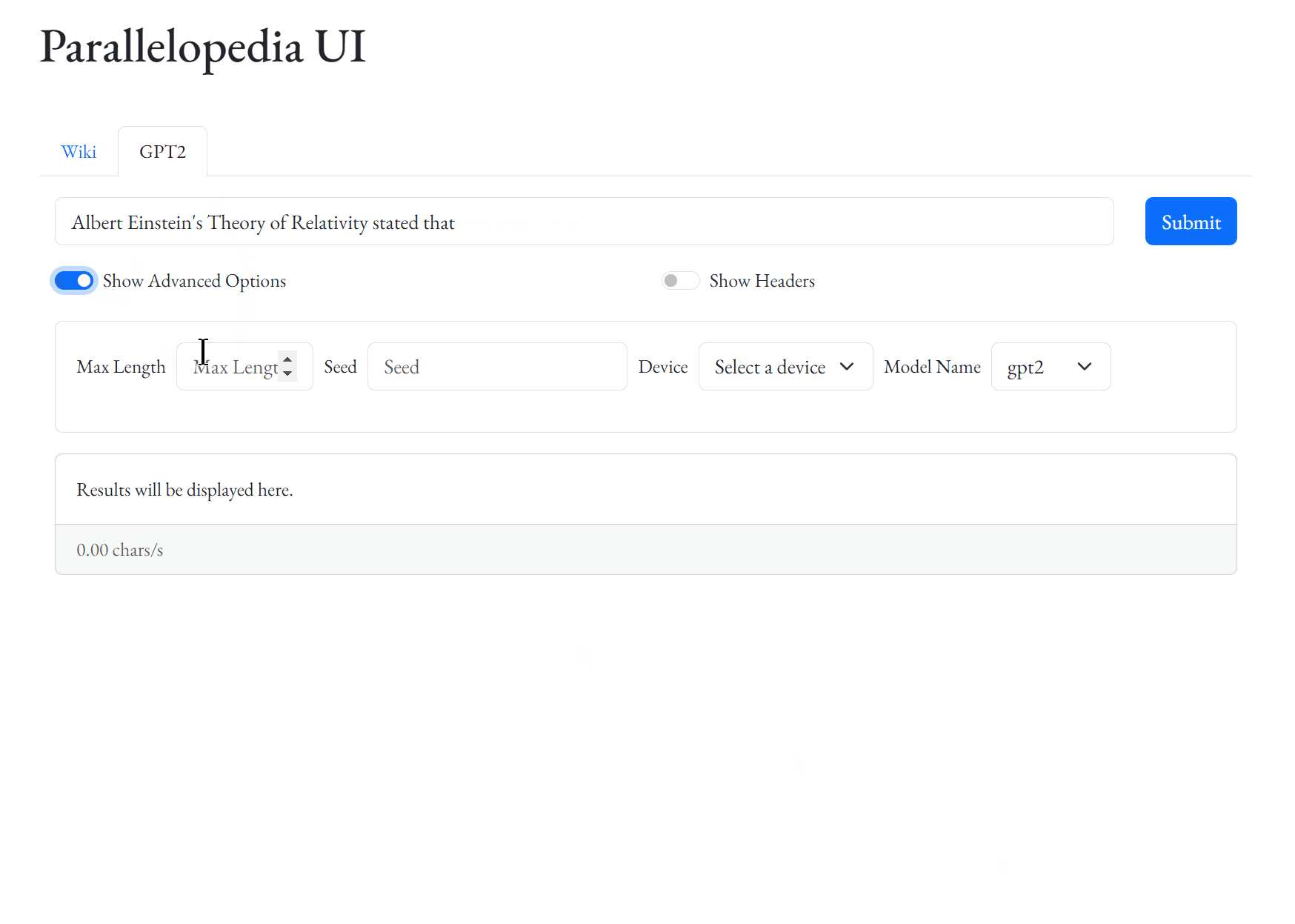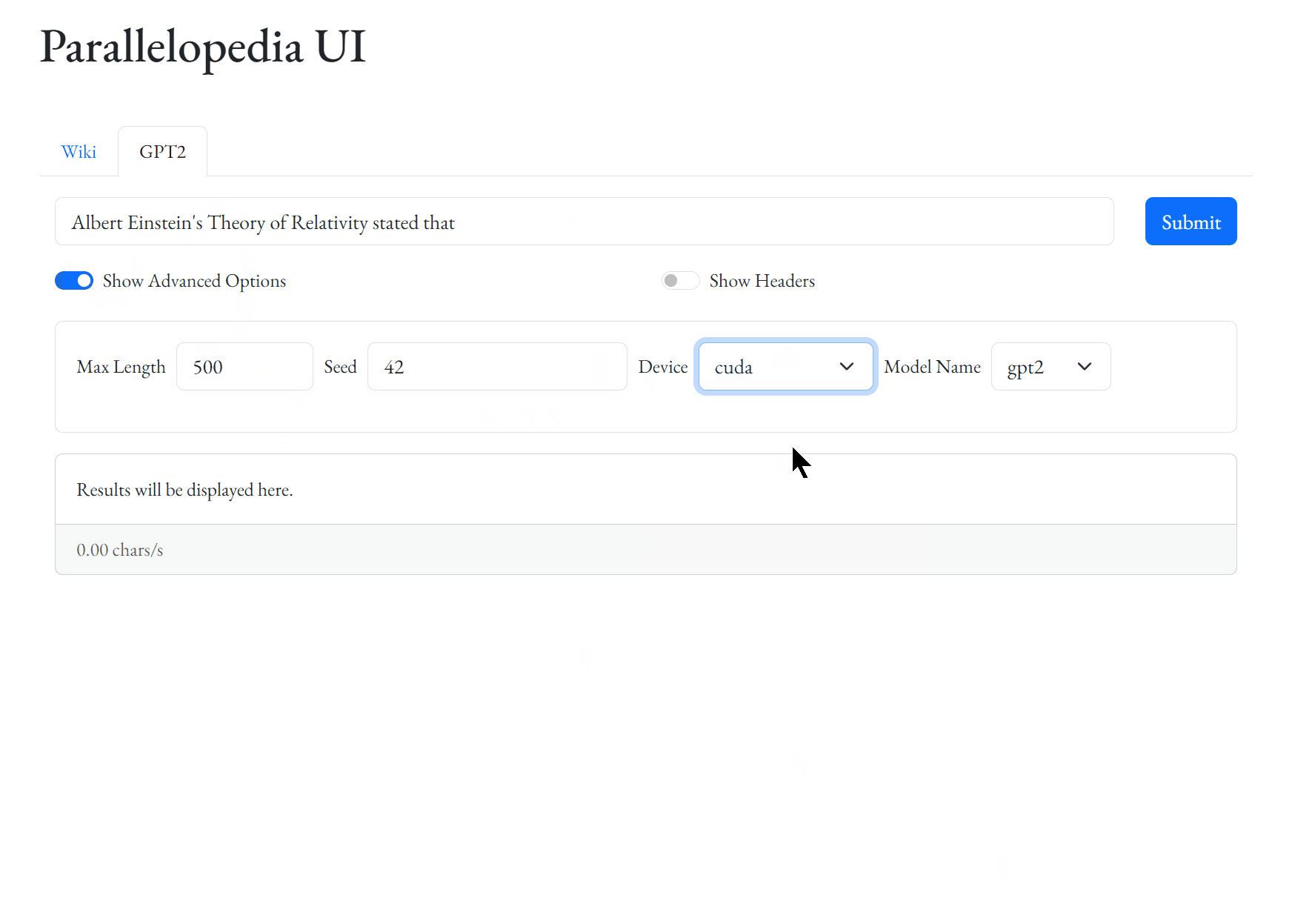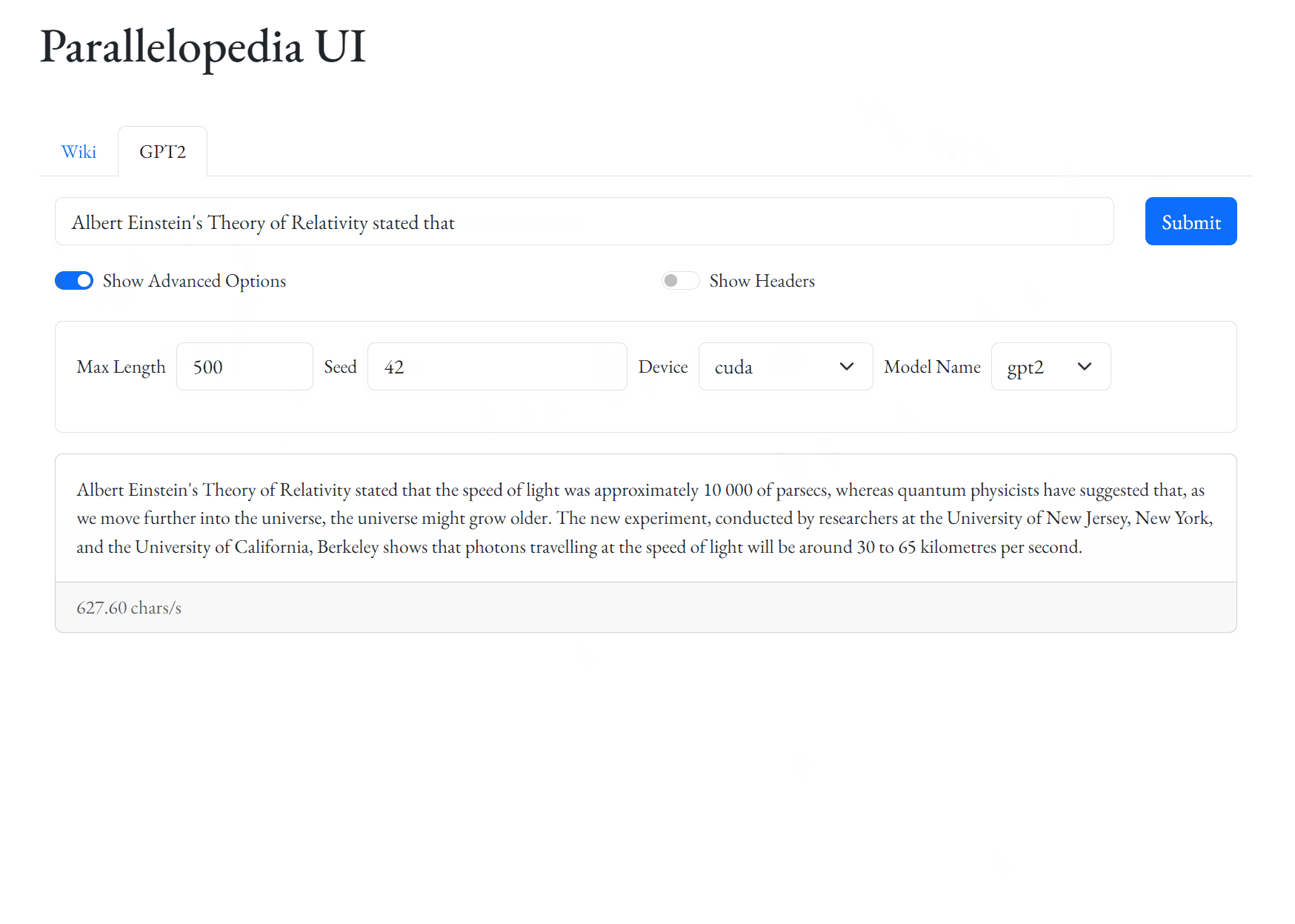
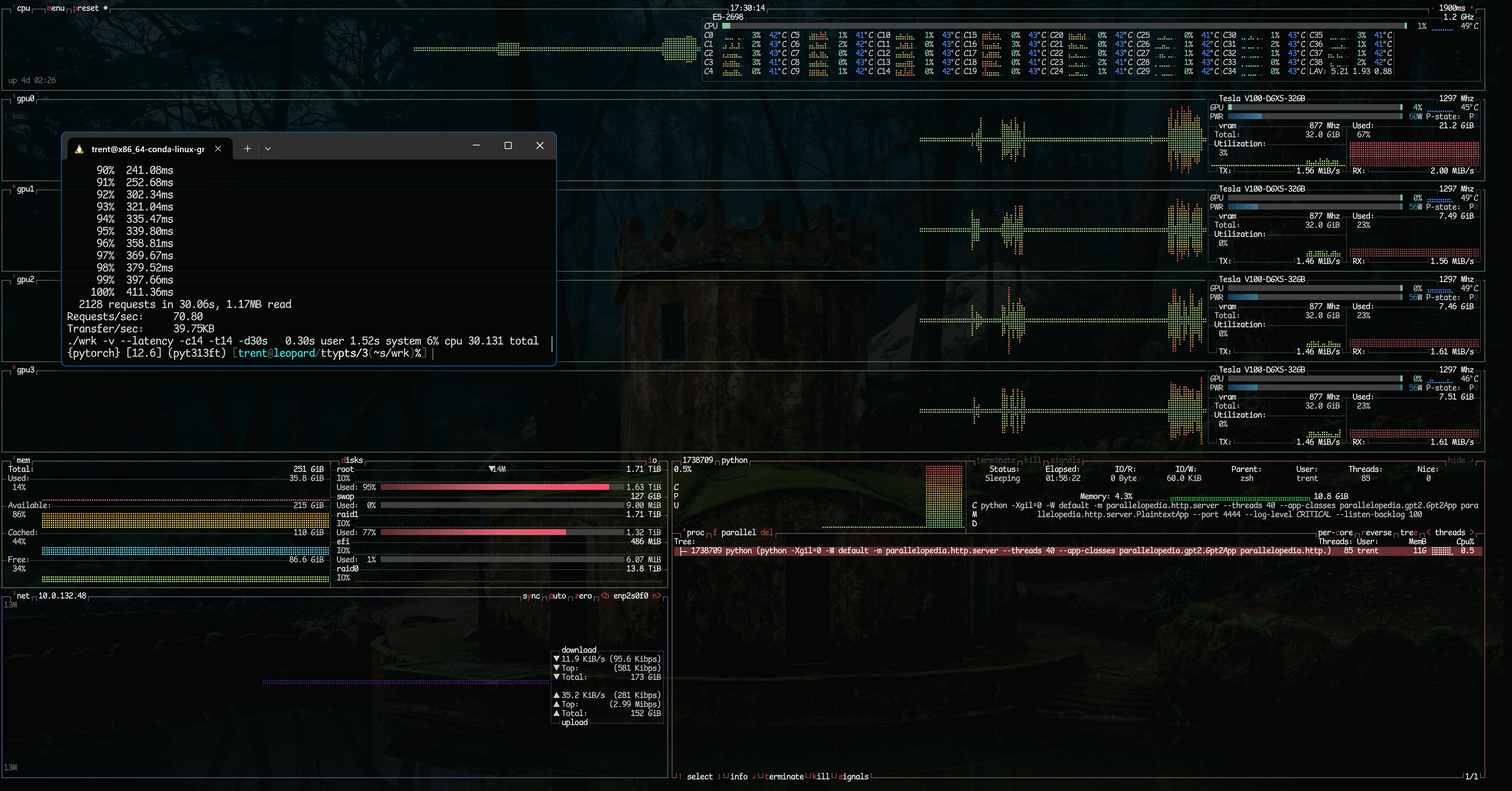
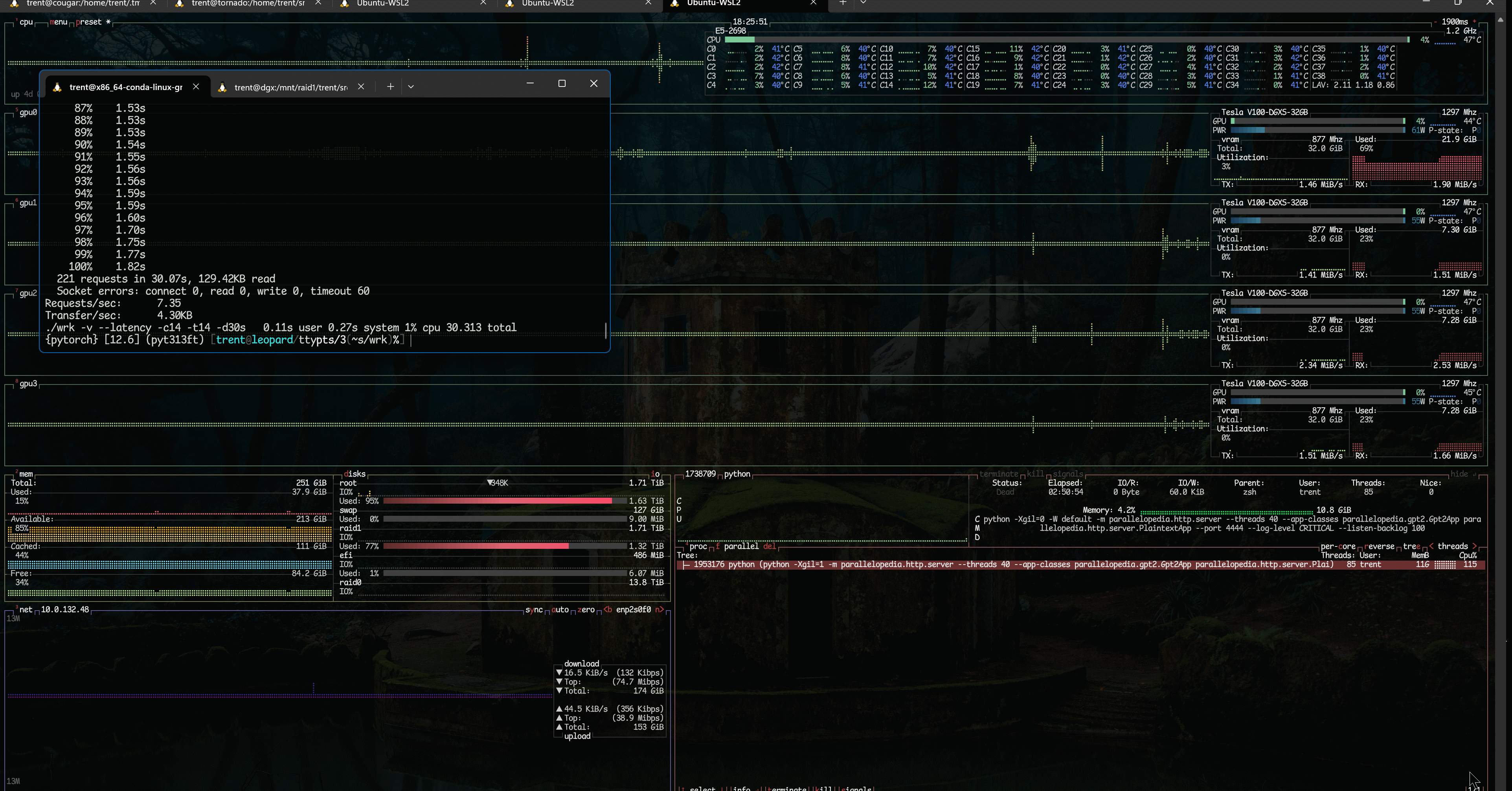
GPT.generate() variants
2025-02-10 20:47:17,958 - INFO - Loaded /mnt/raid1/trent/src/parallelopedia/data/model_19072.pt checkpoint in 0.463 seconds.
2025-02-10 20:47:17,965 - INFO - Initialized GPT model in 0.007 seconds.
2025-02-10 20:47:18,191 - INFO - Loaded model weights in 0.226 seconds.
<frozen importlib._bootstrap>:488: RuntimeWarning: The global interpreter lock (GIL) has been enabled to load module 'triton._C.libtriton', which has not declared that it can run safely without the GIL. To override this behavior and keep the GIL disabled (at your own risk), run with PYTHON_GIL=0 or -Xgil=0.
2025-02-10 20:47:18,558 - INFO - Created GPT model in 0.600 seconds.
2025-02-10 20:47:18,642 - INFO - Moved model to cuda:3 in 0.083 seconds.
2025-02-10 20:47:18,642 - INFO - Loaded model from step 19072, val_loss 3.0519702434539795
2025-02-10 20:47:18,642 - INFO - Loaded gpt2 on cuda:3 in 1.148 seconds.
2025-02-10 20:47:18,642 - INFO - Round 1 of 20.
2025-02-10 20:47:19,454 - INFO - Generated 91 tokens in 0.81 seconds (112.32 tokens/sec)
2025-02-10 20:47:19,454 - INFO - Output:
Einstein's Theory of Relativity states that the speed of
light in a vacuum is simply the speed of the electrons in
that vacuum, since light has a speed. Since the speed of
light in a vacuum is equal to the speed of the electrons in
a solid, the light from this source has a speed of
approximately 1/299,792 m/s. Einstein's theory of relativity
explains this speed by a phenomenon known as the speed at
the end of time. In other words, this speed is
2025-02-10 20:47:19,454 - INFO - Round 2 of 20.
2025-02-10 20:47:20,091 - INFO - Generated 91 tokens in 0.64 seconds (142.89 tokens/sec)
2025-02-10 20:47:20,092 - INFO - Output:
Einstein's Theory of Relativity states that the speed of
light in a vacuum is simply the speed of the electrons in
that vacuum, since light has a speed. Since the speed of
light in a vacuum is equal to the speed of the electrons in
a solid, the light from this source has a speed of
approximately 1/299,792 m/s. Einstein's theory of relativity
explains this speed by a phenomenon known as the speed at
the end of time. In other words, this speed is
2025-02-10 20:47:20,092 - INFO - Round 3 of 20.
2025-02-10 20:47:20,731 - INFO - Generated 91 tokens in 0.64 seconds (142.49 tokens/sec)
2025-02-10 20:47:20,731 - INFO - Output:
Einstein's Theory of Relativity states that the speed of
light in a vacuum is simply the speed of the electrons in
that vacuum, since light has a speed. Since the speed of
light in a vacuum is equal to the speed of the electrons in
a solid, the light from this source has a speed of
approximately 1/299,792 m/s. Einstein's theory of relativity
explains this speed by a phenomenon known as the speed at
the end of time. In other words, this speed is
2025-02-10 20:47:20,731 - INFO - Round 4 of 20.
2025-02-10 20:47:21,366 - INFO - Generated 91 tokens in 0.63 seconds (143.47 tokens/sec)
2025-02-10 20:47:21,366 - INFO - Output:
Einstein's Theory of Relativity states that the speed of
light in a vacuum is simply the speed of the electrons in
that vacuum, since light has a speed. Since the speed of
light in a vacuum is equal to the speed of the electrons in
a solid, the light from this source has a speed of
approximately 1/299,792 m/s. Einstein's theory of relativity
explains this speed by a phenomenon known as the speed at
the end of time. In other words, this speed is
2025-02-10 20:47:21,366 - INFO - Round 5 of 20.
2025-02-10 20:47:22,000 - INFO - Generated 91 tokens in 0.63 seconds (143.62 tokens/sec)
2025-02-10 20:47:22,000 - INFO - Output:
Einstein's Theory of Relativity states that the speed of
light in a vacuum is simply the speed of the electrons in
that vacuum, since light has a speed. Since the speed of
light in a vacuum is equal to the speed of the electrons in
a solid, the light from this source has a speed of
approximately 1/299,792 m/s. Einstein's theory of relativity
explains this speed by a phenomenon known as the speed at
the end of time. In other words, this speed is
2025-02-10 20:47:22,000 - INFO - Round 6 of 20.
2025-02-10 20:47:22,634 - INFO - Generated 91 tokens in 0.63 seconds (143.62 tokens/sec)
2025-02-10 20:47:22,635 - INFO - Output:
Einstein's Theory of Relativity states that the speed of
light in a vacuum is simply the speed of the electrons in
that vacuum, since light has a speed. Since the speed of
light in a vacuum is equal to the speed of the electrons in
a solid, the light from this source has a speed of
approximately 1/299,792 m/s. Einstein's theory of relativity
explains this speed by a phenomenon known as the speed at
the end of time. In other words, this speed is
2025-02-10 20:47:22,635 - INFO - Round 7 of 20.
2025-02-10 20:47:23,270 - INFO - Generated 91 tokens in 0.64 seconds (143.25 tokens/sec)
2025-02-10 20:47:23,271 - INFO - Output:
Einstein's Theory of Relativity states that the speed of
light in a vacuum is simply the speed of the electrons in
that vacuum, since light has a speed. Since the speed of
light in a vacuum is equal to the speed of the electrons in
a solid, the light from this source has a speed of
approximately 1/299,792 m/s. Einstein's theory of relativity
explains this speed by a phenomenon known as the speed at
the end of time. In other words, this speed is
2025-02-10 20:47:23,271 - INFO - Round 8 of 20.
2025-02-10 20:47:23,904 - INFO - Generated 91 tokens in 0.63 seconds (143.67 tokens/sec)
2025-02-10 20:47:23,905 - INFO - Output:
Einstein's Theory of Relativity states that the speed of
light in a vacuum is simply the speed of the electrons in
that vacuum, since light has a speed. Since the speed of
light in a vacuum is equal to the speed of the electrons in
a solid, the light from this source has a speed of
approximately 1/299,792 m/s. Einstein's theory of relativity
explains this speed by a phenomenon known as the speed at
the end of time. In other words, this speed is
2025-02-10 20:47:23,905 - INFO - Round 9 of 20.
2025-02-10 20:47:24,539 - INFO - Generated 91 tokens in 0.63 seconds (143.56 tokens/sec)
2025-02-10 20:47:24,539 - INFO - Output:
Einstein's Theory of Relativity states that the speed of
light in a vacuum is simply the speed of the electrons in
that vacuum, since light has a speed. Since the speed of
light in a vacuum is equal to the speed of the electrons in
a solid, the light from this source has a speed of
approximately 1/299,792 m/s. Einstein's theory of relativity
explains this speed by a phenomenon known as the speed at
the end of time. In other words, this speed is
2025-02-10 20:47:24,539 - INFO - Round 10 of 20.
2025-02-10 20:47:25,174 - INFO - Generated 91 tokens in 0.63 seconds (143.56 tokens/sec)
2025-02-10 20:47:25,174 - INFO - Output:
Einstein's Theory of Relativity states that the speed of
light in a vacuum is simply the speed of the electrons in
that vacuum, since light has a speed. Since the speed of
light in a vacuum is equal to the speed of the electrons in
a solid, the light from this source has a speed of
approximately 1/299,792 m/s. Einstein's theory of relativity
explains this speed by a phenomenon known as the speed at
the end of time. In other words, this speed is
2025-02-10 20:47:25,174 - INFO - Round 11 of 20.
2025-02-10 20:47:25,812 - INFO - Generated 91 tokens in 0.64 seconds (142.78 tokens/sec)
2025-02-10 20:47:25,812 - INFO - Output:
Einstein's Theory of Relativity states that the speed of
light in a vacuum is simply the speed of the electrons in
that vacuum, since light has a speed. Since the speed of
light in a vacuum is equal to the speed of the electrons in
a solid, the light from this source has a speed of
approximately 1/299,792 m/s. Einstein's theory of relativity
explains this speed by a phenomenon known as the speed at
the end of time. In other words, this speed is
2025-02-10 20:47:25,812 - INFO - Round 12 of 20.
2025-02-10 20:47:26,444 - INFO - Generated 91 tokens in 0.63 seconds (143.92 tokens/sec)
2025-02-10 20:47:26,445 - INFO - Output:
Einstein's Theory of Relativity states that the speed of
light in a vacuum is simply the speed of the electrons in
that vacuum, since light has a speed. Since the speed of
light in a vacuum is equal to the speed of the electrons in
a solid, the light from this source has a speed of
approximately 1/299,792 m/s. Einstein's theory of relativity
explains this speed by a phenomenon known as the speed at
the end of time. In other words, this speed is
2025-02-10 20:47:26,445 - INFO - Round 13 of 20.
2025-02-10 20:47:27,080 - INFO - Generated 91 tokens in 0.63 seconds (143.34 tokens/sec)
2025-02-10 20:47:27,080 - INFO - Output:
Einstein's Theory of Relativity states that the speed of
light in a vacuum is simply the speed of the electrons in
that vacuum, since light has a speed. Since the speed of
light in a vacuum is equal to the speed of the electrons in
a solid, the light from this source has a speed of
approximately 1/299,792 m/s. Einstein's theory of relativity
explains this speed by a phenomenon known as the speed at
the end of time. In other words, this speed is
2025-02-10 20:47:27,081 - INFO - Round 14 of 20.
2025-02-10 20:47:27,716 - INFO - Generated 91 tokens in 0.63 seconds (143.34 tokens/sec)
2025-02-10 20:47:27,716 - INFO - Output:
Einstein's Theory of Relativity states that the speed of
light in a vacuum is simply the speed of the electrons in
that vacuum, since light has a speed. Since the speed of
light in a vacuum is equal to the speed of the electrons in
a solid, the light from this source has a speed of
approximately 1/299,792 m/s. Einstein's theory of relativity
explains this speed by a phenomenon known as the speed at
the end of time. In other words, this speed is
2025-02-10 20:47:27,716 - INFO - Round 15 of 20.
2025-02-10 20:47:28,350 - INFO - Generated 91 tokens in 0.63 seconds (143.65 tokens/sec)
2025-02-10 20:47:28,350 - INFO - Output:
Einstein's Theory of Relativity states that the speed of
light in a vacuum is simply the speed of the electrons in
that vacuum, since light has a speed. Since the speed of
light in a vacuum is equal to the speed of the electrons in
a solid, the light from this source has a speed of
approximately 1/299,792 m/s. Einstein's theory of relativity
explains this speed by a phenomenon known as the speed at
the end of time. In other words, this speed is
2025-02-10 20:47:28,350 - INFO - Round 16 of 20.
2025-02-10 20:47:28,984 - INFO - Generated 91 tokens in 0.63 seconds (143.73 tokens/sec)
2025-02-10 20:47:28,984 - INFO - Output:
Einstein's Theory of Relativity states that the speed of
light in a vacuum is simply the speed of the electrons in
that vacuum, since light has a speed. Since the speed of
light in a vacuum is equal to the speed of the electrons in
a solid, the light from this source has a speed of
approximately 1/299,792 m/s. Einstein's theory of relativity
explains this speed by a phenomenon known as the speed at
the end of time. In other words, this speed is
2025-02-10 20:47:28,984 - INFO - Round 17 of 20.
2025-02-10 20:47:29,617 - INFO - Generated 91 tokens in 0.63 seconds (143.79 tokens/sec)
2025-02-10 20:47:29,618 - INFO - Output:
Einstein's Theory of Relativity states that the speed of
light in a vacuum is simply the speed of the electrons in
that vacuum, since light has a speed. Since the speed of
light in a vacuum is equal to the speed of the electrons in
a solid, the light from this source has a speed of
approximately 1/299,792 m/s. Einstein's theory of relativity
explains this speed by a phenomenon known as the speed at
the end of time. In other words, this speed is
2025-02-10 20:47:29,618 - INFO - Round 18 of 20.
2025-02-10 20:47:30,260 - INFO - Generated 91 tokens in 0.64 seconds (141.71 tokens/sec)
2025-02-10 20:47:30,261 - INFO - Output:
Einstein's Theory of Relativity states that the speed of
light in a vacuum is simply the speed of the electrons in
that vacuum, since light has a speed. Since the speed of
light in a vacuum is equal to the speed of the electrons in
a solid, the light from this source has a speed of
approximately 1/299,792 m/s. Einstein's theory of relativity
explains this speed by a phenomenon known as the speed at
the end of time. In other words, this speed is
2025-02-10 20:47:30,261 - INFO - Round 19 of 20.
2025-02-10 20:47:30,896 - INFO - Generated 91 tokens in 0.63 seconds (143.36 tokens/sec)
2025-02-10 20:47:30,896 - INFO - Output:
Einstein's Theory of Relativity states that the speed of
light in a vacuum is simply the speed of the electrons in
that vacuum, since light has a speed. Since the speed of
light in a vacuum is equal to the speed of the electrons in
a solid, the light from this source has a speed of
approximately 1/299,792 m/s. Einstein's theory of relativity
explains this speed by a phenomenon known as the speed at
the end of time. In other words, this speed is
2025-02-10 20:47:30,896 - INFO - Round 20 of 20.
2025-02-10 20:47:31,530 - INFO - Generated 91 tokens in 0.63 seconds (143.55 tokens/sec)
2025-02-10 20:47:31,531 - INFO - Output:
Einstein's Theory of Relativity states that the speed of
light in a vacuum is simply the speed of the electrons in
that vacuum, since light has a speed. Since the speed of
light in a vacuum is equal to the speed of the electrons in
a solid, the light from this source has a speed of
approximately 1/299,792 m/s. Einstein's theory of relativity
explains this speed by a phenomenon known as the speed at
the end of time. In other words, this speed is
2025-02-10 20:47:31,531 - INFO - Run details saved to gpt2-rates-2025-02-10-20-47-31-531204-py313t.json.
torch.__init__: Ignoring unsupported torch.compile() with no GIL unsupported
torch._dynamo.eval_frame: Ignoring unsupported torch.compile() with no GIL unsupported
real 0m19.736s
user 0m22.944s
sys 0m1.382s
Exception ignored in: <_io.BufferedWriter name=41>
BrokenPipeError: [Errno 32] Broken pipe
2025-02-10 20:47:37,663 - INFO - Loaded /mnt/raid1/trent/src/parallelopedia/data/model_19072.pt checkpoint in 0.484 seconds.
2025-02-10 20:47:37,670 - INFO - Initialized GPT model in 0.006 seconds.
2025-02-10 20:47:37,896 - INFO - Loaded model weights in 0.226 seconds.
<frozen importlib._bootstrap>:488: RuntimeWarning: The global interpreter lock (GIL) has been enabled to load module 'triton._C.libtriton', which has not declared that it can run safely without the GIL. To override this behavior and keep the GIL disabled (at your own risk), run with PYTHON_GIL=0 or -Xgil=0.
2025-02-10 20:47:38,263 - INFO - Created GPT model in 0.600 seconds.
2025-02-10 20:47:38,347 - INFO - Moved model to cuda:3 in 0.083 seconds.
2025-02-10 20:47:38,347 - INFO - Loaded model from step 19072, val_loss 3.0519702434539795
2025-02-10 20:47:38,347 - INFO - Loaded gpt2 on cuda:3 in 1.168 seconds.
2025-02-10 20:47:38,349 - INFO - torch.compiled model in 0.002 seconds.
2025-02-10 20:47:38,349 - INFO - Round 1 of 20.
2025-02-10 20:47:39,174 - INFO - Generated 91 tokens in 0.82 seconds (110.47 tokens/sec)
2025-02-10 20:47:39,174 - INFO - Output:
Einstein's Theory of Relativity states that the speed of
light in a vacuum is simply the speed of the electrons in
that vacuum, since light has a speed. Since the speed of
light in a vacuum is equal to the speed of the electrons in
a solid, the light from this source has a speed of
approximately 1/299,792 m/s. Einstein's theory of relativity
explains this speed by a phenomenon known as the speed at
the end of time. In other words, this speed is
2025-02-10 20:47:39,174 - INFO - Round 2 of 20.
2025-02-10 20:47:39,828 - INFO - Generated 91 tokens in 0.65 seconds (139.24 tokens/sec)
2025-02-10 20:47:39,829 - INFO - Output:
Einstein's Theory of Relativity states that the speed of
light in a vacuum is simply the speed of the electrons in
that vacuum, since light has a speed. Since the speed of
light in a vacuum is equal to the speed of the electrons in
a solid, the light from this source has a speed of
approximately 1/299,792 m/s. Einstein's theory of relativity
explains this speed by a phenomenon known as the speed at
the end of time. In other words, this speed is
2025-02-10 20:47:39,829 - INFO - Round 3 of 20.
2025-02-10 20:47:40,483 - INFO - Generated 91 tokens in 0.65 seconds (139.04 tokens/sec)
2025-02-10 20:47:40,484 - INFO - Output:
Einstein's Theory of Relativity states that the speed of
light in a vacuum is simply the speed of the electrons in
that vacuum, since light has a speed. Since the speed of
light in a vacuum is equal to the speed of the electrons in
a solid, the light from this source has a speed of
approximately 1/299,792 m/s. Einstein's theory of relativity
explains this speed by a phenomenon known as the speed at
the end of time. In other words, this speed is
2025-02-10 20:47:40,484 - INFO - Round 4 of 20.
2025-02-10 20:47:41,138 - INFO - Generated 91 tokens in 0.65 seconds (139.23 tokens/sec)
2025-02-10 20:47:41,138 - INFO - Output:
Einstein's Theory of Relativity states that the speed of
light in a vacuum is simply the speed of the electrons in
that vacuum, since light has a speed. Since the speed of
light in a vacuum is equal to the speed of the electrons in
a solid, the light from this source has a speed of
approximately 1/299,792 m/s. Einstein's theory of relativity
explains this speed by a phenomenon known as the speed at
the end of time. In other words, this speed is
2025-02-10 20:47:41,138 - INFO - Round 5 of 20.
2025-02-10 20:47:41,791 - INFO - Generated 91 tokens in 0.65 seconds (139.47 tokens/sec)
2025-02-10 20:47:41,791 - INFO - Output:
Einstein's Theory of Relativity states that the speed of
light in a vacuum is simply the speed of the electrons in
that vacuum, since light has a speed. Since the speed of
light in a vacuum is equal to the speed of the electrons in
a solid, the light from this source has a speed of
approximately 1/299,792 m/s. Einstein's theory of relativity
explains this speed by a phenomenon known as the speed at
the end of time. In other words, this speed is
2025-02-10 20:47:41,791 - INFO - Round 6 of 20.
2025-02-10 20:47:42,445 - INFO - Generated 91 tokens in 0.65 seconds (139.29 tokens/sec)
2025-02-10 20:47:42,445 - INFO - Output:
Einstein's Theory of Relativity states that the speed of
light in a vacuum is simply the speed of the electrons in
that vacuum, since light has a speed. Since the speed of
light in a vacuum is equal to the speed of the electrons in
a solid, the light from this source has a speed of
approximately 1/299,792 m/s. Einstein's theory of relativity
explains this speed by a phenomenon known as the speed at
the end of time. In other words, this speed is
2025-02-10 20:47:42,445 - INFO - Round 7 of 20.
2025-02-10 20:47:43,099 - INFO - Generated 91 tokens in 0.65 seconds (139.09 tokens/sec)
2025-02-10 20:47:43,100 - INFO - Output:
Einstein's Theory of Relativity states that the speed of
light in a vacuum is simply the speed of the electrons in
that vacuum, since light has a speed. Since the speed of
light in a vacuum is equal to the speed of the electrons in
a solid, the light from this source has a speed of
approximately 1/299,792 m/s. Einstein's theory of relativity
explains this speed by a phenomenon known as the speed at
the end of time. In other words, this speed is
2025-02-10 20:47:43,100 - INFO - Round 8 of 20.
2025-02-10 20:47:43,755 - INFO - Generated 91 tokens in 0.66 seconds (138.85 tokens/sec)
2025-02-10 20:47:43,756 - INFO - Output:
Einstein's Theory of Relativity states that the speed of
light in a vacuum is simply the speed of the electrons in
that vacuum, since light has a speed. Since the speed of
light in a vacuum is equal to the speed of the electrons in
a solid, the light from this source has a speed of
approximately 1/299,792 m/s. Einstein's theory of relativity
explains this speed by a phenomenon known as the speed at
the end of time. In other words, this speed is
2025-02-10 20:47:43,756 - INFO - Round 9 of 20.
2025-02-10 20:47:44,409 - INFO - Generated 91 tokens in 0.65 seconds (139.29 tokens/sec)
2025-02-10 20:47:44,410 - INFO - Output:
Einstein's Theory of Relativity states that the speed of
light in a vacuum is simply the speed of the electrons in
that vacuum, since light has a speed. Since the speed of
light in a vacuum is equal to the speed of the electrons in
a solid, the light from this source has a speed of
approximately 1/299,792 m/s. Einstein's theory of relativity
explains this speed by a phenomenon known as the speed at
the end of time. In other words, this speed is
2025-02-10 20:47:44,410 - INFO - Round 10 of 20.
2025-02-10 20:47:45,063 - INFO - Generated 91 tokens in 0.65 seconds (139.29 tokens/sec)
2025-02-10 20:47:45,064 - INFO - Output:
Einstein's Theory of Relativity states that the speed of
light in a vacuum is simply the speed of the electrons in
that vacuum, since light has a speed. Since the speed of
light in a vacuum is equal to the speed of the electrons in
a solid, the light from this source has a speed of
approximately 1/299,792 m/s. Einstein's theory of relativity
explains this speed by a phenomenon known as the speed at
the end of time. In other words, this speed is
2025-02-10 20:47:45,064 - INFO - Round 11 of 20.
2025-02-10 20:47:45,718 - INFO - Generated 91 tokens in 0.65 seconds (139.11 tokens/sec)
2025-02-10 20:47:45,718 - INFO - Output:
Einstein's Theory of Relativity states that the speed of
light in a vacuum is simply the speed of the electrons in
that vacuum, since light has a speed. Since the speed of
light in a vacuum is equal to the speed of the electrons in
a solid, the light from this source has a speed of
approximately 1/299,792 m/s. Einstein's theory of relativity
explains this speed by a phenomenon known as the speed at
the end of time. In other words, this speed is
2025-02-10 20:47:45,719 - INFO - Round 12 of 20.
2025-02-10 20:47:46,371 - INFO - Generated 91 tokens in 0.65 seconds (139.47 tokens/sec)
2025-02-10 20:47:46,372 - INFO - Output:
Einstein's Theory of Relativity states that the speed of
light in a vacuum is simply the speed of the electrons in
that vacuum, since light has a speed. Since the speed of
light in a vacuum is equal to the speed of the electrons in
a solid, the light from this source has a speed of
approximately 1/299,792 m/s. Einstein's theory of relativity
explains this speed by a phenomenon known as the speed at
the end of time. In other words, this speed is
2025-02-10 20:47:46,372 - INFO - Round 13 of 20.
2025-02-10 20:47:47,046 - INFO - Generated 91 tokens in 0.67 seconds (135.03 tokens/sec)
2025-02-10 20:47:47,046 - INFO - Output:
Einstein's Theory of Relativity states that the speed of
light in a vacuum is simply the speed of the electrons in
that vacuum, since light has a speed. Since the speed of
light in a vacuum is equal to the speed of the electrons in
a solid, the light from this source has a speed of
approximately 1/299,792 m/s. Einstein's theory of relativity
explains this speed by a phenomenon known as the speed at
the end of time. In other words, this speed is
2025-02-10 20:47:47,046 - INFO - Round 14 of 20.
2025-02-10 20:47:47,692 - INFO - Generated 91 tokens in 0.65 seconds (140.90 tokens/sec)
2025-02-10 20:47:47,693 - INFO - Output:
Einstein's Theory of Relativity states that the speed of
light in a vacuum is simply the speed of the electrons in
that vacuum, since light has a speed. Since the speed of
light in a vacuum is equal to the speed of the electrons in
a solid, the light from this source has a speed of
approximately 1/299,792 m/s. Einstein's theory of relativity
explains this speed by a phenomenon known as the speed at
the end of time. In other words, this speed is
2025-02-10 20:47:47,693 - INFO - Round 15 of 20.
2025-02-10 20:47:48,339 - INFO - Generated 91 tokens in 0.65 seconds (140.84 tokens/sec)
2025-02-10 20:47:48,339 - INFO - Output:
Einstein's Theory of Relativity states that the speed of
light in a vacuum is simply the speed of the electrons in
that vacuum, since light has a speed. Since the speed of
light in a vacuum is equal to the speed of the electrons in
a solid, the light from this source has a speed of
approximately 1/299,792 m/s. Einstein's theory of relativity
explains this speed by a phenomenon known as the speed at
the end of time. In other words, this speed is
2025-02-10 20:47:48,340 - INFO - Round 16 of 20.
2025-02-10 20:47:48,986 - INFO - Generated 91 tokens in 0.65 seconds (140.90 tokens/sec)
2025-02-10 20:47:48,986 - INFO - Output:
Einstein's Theory of Relativity states that the speed of
light in a vacuum is simply the speed of the electrons in
that vacuum, since light has a speed. Since the speed of
light in a vacuum is equal to the speed of the electrons in
a solid, the light from this source has a speed of
approximately 1/299,792 m/s. Einstein's theory of relativity
explains this speed by a phenomenon known as the speed at
the end of time. In other words, this speed is
2025-02-10 20:47:48,986 - INFO - Round 17 of 20.
2025-02-10 20:47:49,634 - INFO - Generated 91 tokens in 0.65 seconds (140.40 tokens/sec)
2025-02-10 20:47:49,635 - INFO - Output:
Einstein's Theory of Relativity states that the speed of
light in a vacuum is simply the speed of the electrons in
that vacuum, since light has a speed. Since the speed of
light in a vacuum is equal to the speed of the electrons in
a solid, the light from this source has a speed of
approximately 1/299,792 m/s. Einstein's theory of relativity
explains this speed by a phenomenon known as the speed at
the end of time. In other words, this speed is
2025-02-10 20:47:49,635 - INFO - Round 18 of 20.
2025-02-10 20:47:50,282 - INFO - Generated 91 tokens in 0.65 seconds (140.63 tokens/sec)
2025-02-10 20:47:50,283 - INFO - Output:
Einstein's Theory of Relativity states that the speed of
light in a vacuum is simply the speed of the electrons in
that vacuum, since light has a speed. Since the speed of
light in a vacuum is equal to the speed of the electrons in
a solid, the light from this source has a speed of
approximately 1/299,792 m/s. Einstein's theory of relativity
explains this speed by a phenomenon known as the speed at
the end of time. In other words, this speed is
2025-02-10 20:47:50,283 - INFO - Round 19 of 20.
2025-02-10 20:47:50,929 - INFO - Generated 91 tokens in 0.65 seconds (140.73 tokens/sec)
2025-02-10 20:47:50,930 - INFO - Output:
Einstein's Theory of Relativity states that the speed of
light in a vacuum is simply the speed of the electrons in
that vacuum, since light has a speed. Since the speed of
light in a vacuum is equal to the speed of the electrons in
a solid, the light from this source has a speed of
approximately 1/299,792 m/s. Einstein's theory of relativity
explains this speed by a phenomenon known as the speed at
the end of time. In other words, this speed is
2025-02-10 20:47:50,930 - INFO - Round 20 of 20.
2025-02-10 20:47:51,578 - INFO - Generated 91 tokens in 0.65 seconds (140.41 tokens/sec)
2025-02-10 20:47:51,579 - INFO - Output:
Einstein's Theory of Relativity states that the speed of
light in a vacuum is simply the speed of the electrons in
that vacuum, since light has a speed. Since the speed of
light in a vacuum is equal to the speed of the electrons in
a solid, the light from this source has a speed of
approximately 1/299,792 m/s. Einstein's theory of relativity
explains this speed by a phenomenon known as the speed at
the end of time. In other words, this speed is
2025-02-10 20:47:51,579 - INFO - Run details saved to gpt2-rates-2025-02-10-20-47-51-579116-torch-compile-py313t.json.
torch.__init__: Ignoring unsupported torch.compile() with no GIL unsupported
torch._dynamo.eval_frame: Ignoring unsupported torch.compile() with no GIL unsupported
torch.__init__: Ignoring unsupported torch.compile() with no GIL unsupported
torch._dynamo.eval_frame: Ignoring unsupported torch.compile() with no GIL unsupported
real 0m20.073s
user 0m23.400s
sys 0m1.313s
Exception ignored in: <_io.BufferedWriter name=41>
BrokenPipeError: [Errno 32] Broken pipe
2025-02-10 20:47:57,975 - INFO - Loaded /mnt/raid1/trent/src/parallelopedia/data/model_19072.pt checkpoint in 0.486 seconds.
2025-02-10 20:47:57,982 - INFO - Initialized GPT model in 0.006 seconds.
2025-02-10 20:47:58,209 - INFO - Loaded model weights in 0.227 seconds.
<frozen importlib._bootstrap>:488: RuntimeWarning: The global interpreter lock (GIL) has been enabled to load module 'triton._C.libtriton', which has not declared that it can run safely without the GIL. To override this behavior and keep the GIL disabled (at your own risk), run with PYTHON_GIL=0 or -Xgil=0.
2025-02-10 20:47:58,575 - INFO - Created GPT model in 0.599 seconds.
2025-02-10 20:47:58,659 - INFO - Moved model to cuda:3 in 0.084 seconds.
2025-02-10 20:47:58,659 - INFO - Loaded model from step 19072, val_loss 3.0519702434539795
2025-02-10 20:47:58,659 - INFO - Loaded gpt2 on cuda:3 in 1.170 seconds.
2025-02-10 20:47:58,660 - INFO - torch.compiled model in 0.001 seconds.
2025-02-10 20:47:58,661 - INFO - Round 1 of 20.
2025-02-10 20:47:59,483 - INFO - Generated 91 tokens in 0.82 seconds (110.79 tokens/sec)
2025-02-10 20:47:59,483 - INFO - Output:
Einstein's Theory of Relativity states that the speed of
light in a vacuum is simply the speed of the electrons in
that vacuum, since light has a speed. Since the speed of
light in a vacuum is equal to the speed of the electrons in
a solid, the light from this source has a speed of
approximately 1/299,792 m/s. Einstein's theory of relativity
explains this speed by a phenomenon known as the speed at
the end of time. In other words, this speed is
2025-02-10 20:47:59,483 - INFO - Round 2 of 20.
2025-02-10 20:48:00,153 - INFO - Generated 91 tokens in 0.67 seconds (135.92 tokens/sec)
2025-02-10 20:48:00,153 - INFO - Output:
Einstein's Theory of Relativity states that the speed of
light in a vacuum is simply the speed of the electrons in
that vacuum, since light has a speed. Since the speed of
light in a vacuum is equal to the speed of the electrons in
a solid, the light from this source has a speed of
approximately 1/299,792 m/s. Einstein's theory of relativity
explains this speed by a phenomenon known as the speed at
the end of time. In other words, this speed is
2025-02-10 20:48:00,153 - INFO - Round 3 of 20.
2025-02-10 20:48:00,796 - INFO - Generated 91 tokens in 0.64 seconds (141.66 tokens/sec)
2025-02-10 20:48:00,796 - INFO - Output:
Einstein's Theory of Relativity states that the speed of
light in a vacuum is simply the speed of the electrons in
that vacuum, since light has a speed. Since the speed of
light in a vacuum is equal to the speed of the electrons in
a solid, the light from this source has a speed of
approximately 1/299,792 m/s. Einstein's theory of relativity
explains this speed by a phenomenon known as the speed at
the end of time. In other words, this speed is
2025-02-10 20:48:00,796 - INFO - Round 4 of 20.
2025-02-10 20:48:01,439 - INFO - Generated 91 tokens in 0.64 seconds (141.69 tokens/sec)
2025-02-10 20:48:01,439 - INFO - Output:
Einstein's Theory of Relativity states that the speed of
light in a vacuum is simply the speed of the electrons in
that vacuum, since light has a speed. Since the speed of
light in a vacuum is equal to the speed of the electrons in
a solid, the light from this source has a speed of
approximately 1/299,792 m/s. Einstein's theory of relativity
explains this speed by a phenomenon known as the speed at
the end of time. In other words, this speed is
2025-02-10 20:48:01,439 - INFO - Round 5 of 20.
2025-02-10 20:48:02,086 - INFO - Generated 91 tokens in 0.65 seconds (140.83 tokens/sec)
2025-02-10 20:48:02,086 - INFO - Output:
Einstein's Theory of Relativity states that the speed of
light in a vacuum is simply the speed of the electrons in
that vacuum, since light has a speed. Since the speed of
light in a vacuum is equal to the speed of the electrons in
a solid, the light from this source has a speed of
approximately 1/299,792 m/s. Einstein's theory of relativity
explains this speed by a phenomenon known as the speed at
the end of time. In other words, this speed is
2025-02-10 20:48:02,086 - INFO - Round 6 of 20.
2025-02-10 20:48:02,730 - INFO - Generated 91 tokens in 0.64 seconds (141.33 tokens/sec)
2025-02-10 20:48:02,731 - INFO - Output:
Einstein's Theory of Relativity states that the speed of
light in a vacuum is simply the speed of the electrons in
that vacuum, since light has a speed. Since the speed of
light in a vacuum is equal to the speed of the electrons in
a solid, the light from this source has a speed of
approximately 1/299,792 m/s. Einstein's theory of relativity
explains this speed by a phenomenon known as the speed at
the end of time. In other words, this speed is
2025-02-10 20:48:02,731 - INFO - Round 7 of 20.
2025-02-10 20:48:03,374 - INFO - Generated 91 tokens in 0.64 seconds (141.45 tokens/sec)
2025-02-10 20:48:03,375 - INFO - Output:
Einstein's Theory of Relativity states that the speed of
light in a vacuum is simply the speed of the electrons in
that vacuum, since light has a speed. Since the speed of
light in a vacuum is equal to the speed of the electrons in
a solid, the light from this source has a speed of
approximately 1/299,792 m/s. Einstein's theory of relativity
explains this speed by a phenomenon known as the speed at
the end of time. In other words, this speed is
2025-02-10 20:48:03,375 - INFO - Round 8 of 20.
2025-02-10 20:48:04,017 - INFO - Generated 91 tokens in 0.64 seconds (141.76 tokens/sec)
2025-02-10 20:48:04,017 - INFO - Output:
Einstein's Theory of Relativity states that the speed of
light in a vacuum is simply the speed of the electrons in
that vacuum, since light has a speed. Since the speed of
light in a vacuum is equal to the speed of the electrons in
a solid, the light from this source has a speed of
approximately 1/299,792 m/s. Einstein's theory of relativity
explains this speed by a phenomenon known as the speed at
the end of time. In other words, this speed is
2025-02-10 20:48:04,017 - INFO - Round 9 of 20.
2025-02-10 20:48:04,661 - INFO - Generated 91 tokens in 0.64 seconds (141.46 tokens/sec)
2025-02-10 20:48:04,661 - INFO - Output:
Einstein's Theory of Relativity states that the speed of
light in a vacuum is simply the speed of the electrons in
that vacuum, since light has a speed. Since the speed of
light in a vacuum is equal to the speed of the electrons in
a solid, the light from this source has a speed of
approximately 1/299,792 m/s. Einstein's theory of relativity
explains this speed by a phenomenon known as the speed at
the end of time. In other words, this speed is
2025-02-10 20:48:04,661 - INFO - Round 10 of 20.
2025-02-10 20:48:05,303 - INFO - Generated 91 tokens in 0.64 seconds (141.82 tokens/sec)
2025-02-10 20:48:05,303 - INFO - Output:
Einstein's Theory of Relativity states that the speed of
light in a vacuum is simply the speed of the electrons in
that vacuum, since light has a speed. Since the speed of
light in a vacuum is equal to the speed of the electrons in
a solid, the light from this source has a speed of
approximately 1/299,792 m/s. Einstein's theory of relativity
explains this speed by a phenomenon known as the speed at
the end of time. In other words, this speed is
2025-02-10 20:48:05,303 - INFO - Round 11 of 20.
2025-02-10 20:48:05,945 - INFO - Generated 91 tokens in 0.64 seconds (141.91 tokens/sec)
2025-02-10 20:48:05,945 - INFO - Output:
Einstein's Theory of Relativity states that the speed of
light in a vacuum is simply the speed of the electrons in
that vacuum, since light has a speed. Since the speed of
light in a vacuum is equal to the speed of the electrons in
a solid, the light from this source has a speed of
approximately 1/299,792 m/s. Einstein's theory of relativity
explains this speed by a phenomenon known as the speed at
the end of time. In other words, this speed is
2025-02-10 20:48:05,945 - INFO - Round 12 of 20.
2025-02-10 20:48:06,587 - INFO - Generated 91 tokens in 0.64 seconds (141.83 tokens/sec)
2025-02-10 20:48:06,587 - INFO - Output:
Einstein's Theory of Relativity states that the speed of
light in a vacuum is simply the speed of the electrons in
that vacuum, since light has a speed. Since the speed of
light in a vacuum is equal to the speed of the electrons in
a solid, the light from this source has a speed of
approximately 1/299,792 m/s. Einstein's theory of relativity
explains this speed by a phenomenon known as the speed at
the end of time. In other words, this speed is
2025-02-10 20:48:06,587 - INFO - Round 13 of 20.
2025-02-10 20:48:07,229 - INFO - Generated 91 tokens in 0.64 seconds (141.93 tokens/sec)
2025-02-10 20:48:07,229 - INFO - Output:
Einstein's Theory of Relativity states that the speed of
light in a vacuum is simply the speed of the electrons in
that vacuum, since light has a speed. Since the speed of
light in a vacuum is equal to the speed of the electrons in
a solid, the light from this source has a speed of
approximately 1/299,792 m/s. Einstein's theory of relativity
explains this speed by a phenomenon known as the speed at
the end of time. In other words, this speed is
2025-02-10 20:48:07,229 - INFO - Round 14 of 20.
2025-02-10 20:48:07,871 - INFO - Generated 91 tokens in 0.64 seconds (141.88 tokens/sec)
2025-02-10 20:48:07,871 - INFO - Output:
Einstein's Theory of Relativity states that the speed of
light in a vacuum is simply the speed of the electrons in
that vacuum, since light has a speed. Since the speed of
light in a vacuum is equal to the speed of the electrons in
a solid, the light from this source has a speed of
approximately 1/299,792 m/s. Einstein's theory of relativity
explains this speed by a phenomenon known as the speed at
the end of time. In other words, this speed is
2025-02-10 20:48:07,871 - INFO - Round 15 of 20.
2025-02-10 20:48:08,513 - INFO - Generated 91 tokens in 0.64 seconds (141.74 tokens/sec)
2025-02-10 20:48:08,514 - INFO - Output:
Einstein's Theory of Relativity states that the speed of
light in a vacuum is simply the speed of the electrons in
that vacuum, since light has a speed. Since the speed of
light in a vacuum is equal to the speed of the electrons in
a solid, the light from this source has a speed of
approximately 1/299,792 m/s. Einstein's theory of relativity
explains this speed by a phenomenon known as the speed at
the end of time. In other words, this speed is
2025-02-10 20:48:08,514 - INFO - Round 16 of 20.
2025-02-10 20:48:09,157 - INFO - Generated 91 tokens in 0.64 seconds (141.58 tokens/sec)
2025-02-10 20:48:09,157 - INFO - Output:
Einstein's Theory of Relativity states that the speed of
light in a vacuum is simply the speed of the electrons in
that vacuum, since light has a speed. Since the speed of
light in a vacuum is equal to the speed of the electrons in
a solid, the light from this source has a speed of
approximately 1/299,792 m/s. Einstein's theory of relativity
explains this speed by a phenomenon known as the speed at
the end of time. In other words, this speed is
2025-02-10 20:48:09,157 - INFO - Round 17 of 20.
2025-02-10 20:48:09,799 - INFO - Generated 91 tokens in 0.64 seconds (141.79 tokens/sec)
2025-02-10 20:48:09,800 - INFO - Output:
Einstein's Theory of Relativity states that the speed of
light in a vacuum is simply the speed of the electrons in
that vacuum, since light has a speed. Since the speed of
light in a vacuum is equal to the speed of the electrons in
a solid, the light from this source has a speed of
approximately 1/299,792 m/s. Einstein's theory of relativity
explains this speed by a phenomenon known as the speed at
the end of time. In other words, this speed is
2025-02-10 20:48:09,800 - INFO - Round 18 of 20.
2025-02-10 20:48:10,442 - INFO - Generated 91 tokens in 0.64 seconds (141.75 tokens/sec)
2025-02-10 20:48:10,442 - INFO - Output:
Einstein's Theory of Relativity states that the speed of
light in a vacuum is simply the speed of the electrons in
that vacuum, since light has a speed. Since the speed of
light in a vacuum is equal to the speed of the electrons in
a solid, the light from this source has a speed of
approximately 1/299,792 m/s. Einstein's theory of relativity
explains this speed by a phenomenon known as the speed at
the end of time. In other words, this speed is
2025-02-10 20:48:10,442 - INFO - Round 19 of 20.
2025-02-10 20:48:11,084 - INFO - Generated 91 tokens in 0.64 seconds (141.77 tokens/sec)
2025-02-10 20:48:11,085 - INFO - Output:
Einstein's Theory of Relativity states that the speed of
light in a vacuum is simply the speed of the electrons in
that vacuum, since light has a speed. Since the speed of
light in a vacuum is equal to the speed of the electrons in
a solid, the light from this source has a speed of
approximately 1/299,792 m/s. Einstein's theory of relativity
explains this speed by a phenomenon known as the speed at
the end of time. In other words, this speed is
2025-02-10 20:48:11,085 - INFO - Round 20 of 20.
2025-02-10 20:48:11,727 - INFO - Generated 91 tokens in 0.64 seconds (141.75 tokens/sec)
2025-02-10 20:48:11,727 - INFO - Output:
Einstein's Theory of Relativity states that the speed of
light in a vacuum is simply the speed of the electrons in
that vacuum, since light has a speed. Since the speed of
light in a vacuum is equal to the speed of the electrons in
a solid, the light from this source has a speed of
approximately 1/299,792 m/s. Einstein's theory of relativity
explains this speed by a phenomenon known as the speed at
the end of time. In other words, this speed is
2025-02-10 20:48:11,728 - INFO - Run details saved to gpt2-rates-2025-02-10-20-48-11-727901-torch-compile-fullgraph-py313t.json.
torch.__init__: Ignoring unsupported torch.compile() with no GIL unsupported
torch._dynamo.eval_frame: Ignoring unsupported torch.compile() with no GIL unsupported
torch.__init__: Ignoring unsupported torch.compile() with no GIL unsupported
torch._dynamo.eval_frame: Ignoring unsupported torch.compile() with no GIL unsupported
real 0m20.125s
user 0m23.218s
sys 0m1.382s
Exception ignored in: <_io.BufferedWriter name=41>
BrokenPipeError: [Errno 32] Broken pipe
2025-02-10 20:48:17,900 - INFO - Loaded /mnt/raid1/trent/src/parallelopedia/data/model_19072.pt checkpoint in 0.486 seconds.
2025-02-10 20:48:17,907 - INFO - Initialized GPT model in 0.006 seconds.
2025-02-10 20:48:18,132 - INFO - Loaded model weights in 0.225 seconds.
<frozen importlib._bootstrap>:488: RuntimeWarning: The global interpreter lock (GIL) has been enabled to load module 'triton._C.libtriton', which has not declared that it can run safely without the GIL. To override this behavior and keep the GIL disabled (at your own risk), run with PYTHON_GIL=0 or -Xgil=0.
2025-02-10 20:48:18,494 - INFO - Created GPT model in 0.594 seconds.
2025-02-10 20:48:18,577 - INFO - Moved model to cuda:3 in 0.082 seconds.
2025-02-10 20:48:18,577 - INFO - Loaded model from step 19072, val_loss 3.0519702434539795
2025-02-10 20:48:18,577 - INFO - Loaded gpt2 on cuda:3 in 1.162 seconds.
2025-02-10 20:48:18,581 - INFO - torch.compiled model in 0.004 seconds.
2025-02-10 20:48:18,581 - INFO - Round 1 of 20.
2025-02-10 20:48:19,397 - INFO - Generated 91 tokens in 0.82 seconds (111.57 tokens/sec)
2025-02-10 20:48:19,398 - INFO - Output:
Einstein's Theory of Relativity states that the speed of
light in a vacuum is simply the speed of the electrons in
that vacuum, since light has a speed. Since the speed of
light in a vacuum is equal to the speed of the electrons in
a solid, the light from this source has a speed of
approximately 1/299,792 m/s. Einstein's theory of relativity
explains this speed by a phenomenon known as the speed at
the end of time. In other words, this speed is
2025-02-10 20:48:19,398 - INFO - Round 2 of 20.
2025-02-10 20:48:20,044 - INFO - Generated 91 tokens in 0.65 seconds (140.99 tokens/sec)
2025-02-10 20:48:20,044 - INFO - Output:
Einstein's Theory of Relativity states that the speed of
light in a vacuum is simply the speed of the electrons in
that vacuum, since light has a speed. Since the speed of
light in a vacuum is equal to the speed of the electrons in
a solid, the light from this source has a speed of
approximately 1/299,792 m/s. Einstein's theory of relativity
explains this speed by a phenomenon known as the speed at
the end of time. In other words, this speed is
2025-02-10 20:48:20,044 - INFO - Round 3 of 20.
2025-02-10 20:48:20,690 - INFO - Generated 91 tokens in 0.65 seconds (140.95 tokens/sec)
2025-02-10 20:48:20,690 - INFO - Output:
Einstein's Theory of Relativity states that the speed of
light in a vacuum is simply the speed of the electrons in
that vacuum, since light has a speed. Since the speed of
light in a vacuum is equal to the speed of the electrons in
a solid, the light from this source has a speed of
approximately 1/299,792 m/s. Einstein's theory of relativity
explains this speed by a phenomenon known as the speed at
the end of time. In other words, this speed is
2025-02-10 20:48:20,690 - INFO - Round 4 of 20.
2025-02-10 20:48:21,335 - INFO - Generated 91 tokens in 0.64 seconds (141.16 tokens/sec)
2025-02-10 20:48:21,336 - INFO - Output:
Einstein's Theory of Relativity states that the speed of
light in a vacuum is simply the speed of the electrons in
that vacuum, since light has a speed. Since the speed of
light in a vacuum is equal to the speed of the electrons in
a solid, the light from this source has a speed of
approximately 1/299,792 m/s. Einstein's theory of relativity
explains this speed by a phenomenon known as the speed at
the end of time. In other words, this speed is
2025-02-10 20:48:21,336 - INFO - Round 5 of 20.
2025-02-10 20:48:21,981 - INFO - Generated 91 tokens in 0.64 seconds (141.10 tokens/sec)
2025-02-10 20:48:21,981 - INFO - Output:
Einstein's Theory of Relativity states that the speed of
light in a vacuum is simply the speed of the electrons in
that vacuum, since light has a speed. Since the speed of
light in a vacuum is equal to the speed of the electrons in
a solid, the light from this source has a speed of
approximately 1/299,792 m/s. Einstein's theory of relativity
explains this speed by a phenomenon known as the speed at
the end of time. In other words, this speed is
2025-02-10 20:48:21,981 - INFO - Round 6 of 20.
2025-02-10 20:48:22,627 - INFO - Generated 91 tokens in 0.65 seconds (141.03 tokens/sec)
2025-02-10 20:48:22,627 - INFO - Output:
Einstein's Theory of Relativity states that the speed of
light in a vacuum is simply the speed of the electrons in
that vacuum, since light has a speed. Since the speed of
light in a vacuum is equal to the speed of the electrons in
a solid, the light from this source has a speed of
approximately 1/299,792 m/s. Einstein's theory of relativity
explains this speed by a phenomenon known as the speed at
the end of time. In other words, this speed is
2025-02-10 20:48:22,627 - INFO - Round 7 of 20.
2025-02-10 20:48:23,274 - INFO - Generated 91 tokens in 0.65 seconds (140.67 tokens/sec)
2025-02-10 20:48:23,275 - INFO - Output:
Einstein's Theory of Relativity states that the speed of
light in a vacuum is simply the speed of the electrons in
that vacuum, since light has a speed. Since the speed of
light in a vacuum is equal to the speed of the electrons in
a solid, the light from this source has a speed of
approximately 1/299,792 m/s. Einstein's theory of relativity
explains this speed by a phenomenon known as the speed at
the end of time. In other words, this speed is
2025-02-10 20:48:23,275 - INFO - Round 8 of 20.
2025-02-10 20:48:23,950 - INFO - Generated 91 tokens in 0.68 seconds (134.77 tokens/sec)
2025-02-10 20:48:23,950 - INFO - Output:
Einstein's Theory of Relativity states that the speed of
light in a vacuum is simply the speed of the electrons in
that vacuum, since light has a speed. Since the speed of
light in a vacuum is equal to the speed of the electrons in
a solid, the light from this source has a speed of
approximately 1/299,792 m/s. Einstein's theory of relativity
explains this speed by a phenomenon known as the speed at
the end of time. In other words, this speed is
2025-02-10 20:48:23,951 - INFO - Round 9 of 20.
2025-02-10 20:48:24,637 - INFO - Generated 91 tokens in 0.69 seconds (132.66 tokens/sec)
2025-02-10 20:48:24,637 - INFO - Output:
Einstein's Theory of Relativity states that the speed of
light in a vacuum is simply the speed of the electrons in
that vacuum, since light has a speed. Since the speed of
light in a vacuum is equal to the speed of the electrons in
a solid, the light from this source has a speed of
approximately 1/299,792 m/s. Einstein's theory of relativity
explains this speed by a phenomenon known as the speed at
the end of time. In other words, this speed is
2025-02-10 20:48:24,637 - INFO - Round 10 of 20.
2025-02-10 20:48:25,293 - INFO - Generated 91 tokens in 0.66 seconds (138.78 tokens/sec)
2025-02-10 20:48:25,294 - INFO - Output:
Einstein's Theory of Relativity states that the speed of
light in a vacuum is simply the speed of the electrons in
that vacuum, since light has a speed. Since the speed of
light in a vacuum is equal to the speed of the electrons in
a solid, the light from this source has a speed of
approximately 1/299,792 m/s. Einstein's theory of relativity
explains this speed by a phenomenon known as the speed at
the end of time. In other words, this speed is
2025-02-10 20:48:25,294 - INFO - Round 11 of 20.
2025-02-10 20:48:25,952 - INFO - Generated 91 tokens in 0.66 seconds (138.35 tokens/sec)
2025-02-10 20:48:25,952 - INFO - Output:
Einstein's Theory of Relativity states that the speed of
light in a vacuum is simply the speed of the electrons in
that vacuum, since light has a speed. Since the speed of
light in a vacuum is equal to the speed of the electrons in
a solid, the light from this source has a speed of
approximately 1/299,792 m/s. Einstein's theory of relativity
explains this speed by a phenomenon known as the speed at
the end of time. In other words, this speed is
2025-02-10 20:48:25,952 - INFO - Round 12 of 20.
2025-02-10 20:48:26,609 - INFO - Generated 91 tokens in 0.66 seconds (138.65 tokens/sec)
2025-02-10 20:48:26,609 - INFO - Output:
Einstein's Theory of Relativity states that the speed of
light in a vacuum is simply the speed of the electrons in
that vacuum, since light has a speed. Since the speed of
light in a vacuum is equal to the speed of the electrons in
a solid, the light from this source has a speed of
approximately 1/299,792 m/s. Einstein's theory of relativity
explains this speed by a phenomenon known as the speed at
the end of time. In other words, this speed is
2025-02-10 20:48:26,609 - INFO - Round 13 of 20.
2025-02-10 20:48:27,265 - INFO - Generated 91 tokens in 0.66 seconds (138.73 tokens/sec)
2025-02-10 20:48:27,265 - INFO - Output:
Einstein's Theory of Relativity states that the speed of
light in a vacuum is simply the speed of the electrons in
that vacuum, since light has a speed. Since the speed of
light in a vacuum is equal to the speed of the electrons in
a solid, the light from this source has a speed of
approximately 1/299,792 m/s. Einstein's theory of relativity
explains this speed by a phenomenon known as the speed at
the end of time. In other words, this speed is
2025-02-10 20:48:27,265 - INFO - Round 14 of 20.
2025-02-10 20:48:27,922 - INFO - Generated 91 tokens in 0.66 seconds (138.71 tokens/sec)
2025-02-10 20:48:27,922 - INFO - Output:
Einstein's Theory of Relativity states that the speed of
light in a vacuum is simply the speed of the electrons in
that vacuum, since light has a speed. Since the speed of
light in a vacuum is equal to the speed of the electrons in
a solid, the light from this source has a speed of
approximately 1/299,792 m/s. Einstein's theory of relativity
explains this speed by a phenomenon known as the speed at
the end of time. In other words, this speed is
2025-02-10 20:48:27,922 - INFO - Round 15 of 20.
2025-02-10 20:48:28,579 - INFO - Generated 91 tokens in 0.66 seconds (138.54 tokens/sec)
2025-02-10 20:48:28,580 - INFO - Output:
Einstein's Theory of Relativity states that the speed of
light in a vacuum is simply the speed of the electrons in
that vacuum, since light has a speed. Since the speed of
light in a vacuum is equal to the speed of the electrons in
a solid, the light from this source has a speed of
approximately 1/299,792 m/s. Einstein's theory of relativity
explains this speed by a phenomenon known as the speed at
the end of time. In other words, this speed is
2025-02-10 20:48:28,580 - INFO - Round 16 of 20.
2025-02-10 20:48:29,236 - INFO - Generated 91 tokens in 0.66 seconds (138.70 tokens/sec)
2025-02-10 20:48:29,236 - INFO - Output:
Einstein's Theory of Relativity states that the speed of
light in a vacuum is simply the speed of the electrons in
that vacuum, since light has a speed. Since the speed of
light in a vacuum is equal to the speed of the electrons in
a solid, the light from this source has a speed of
approximately 1/299,792 m/s. Einstein's theory of relativity
explains this speed by a phenomenon known as the speed at
the end of time. In other words, this speed is
2025-02-10 20:48:29,236 - INFO - Round 17 of 20.
2025-02-10 20:48:29,894 - INFO - Generated 91 tokens in 0.66 seconds (138.52 tokens/sec)
2025-02-10 20:48:29,894 - INFO - Output:
Einstein's Theory of Relativity states that the speed of
light in a vacuum is simply the speed of the electrons in
that vacuum, since light has a speed. Since the speed of
light in a vacuum is equal to the speed of the electrons in
a solid, the light from this source has a speed of
approximately 1/299,792 m/s. Einstein's theory of relativity
explains this speed by a phenomenon known as the speed at
the end of time. In other words, this speed is
2025-02-10 20:48:29,894 - INFO - Round 18 of 20.
2025-02-10 20:48:30,550 - INFO - Generated 91 tokens in 0.66 seconds (138.78 tokens/sec)
2025-02-10 20:48:30,550 - INFO - Output:
Einstein's Theory of Relativity states that the speed of
light in a vacuum is simply the speed of the electrons in
that vacuum, since light has a speed. Since the speed of
light in a vacuum is equal to the speed of the electrons in
a solid, the light from this source has a speed of
approximately 1/299,792 m/s. Einstein's theory of relativity
explains this speed by a phenomenon known as the speed at
the end of time. In other words, this speed is
2025-02-10 20:48:30,550 - INFO - Round 19 of 20.
2025-02-10 20:48:31,208 - INFO - Generated 91 tokens in 0.66 seconds (138.36 tokens/sec)
2025-02-10 20:48:31,209 - INFO - Output:
Einstein's Theory of Relativity states that the speed of
light in a vacuum is simply the speed of the electrons in
that vacuum, since light has a speed. Since the speed of
light in a vacuum is equal to the speed of the electrons in
a solid, the light from this source has a speed of
approximately 1/299,792 m/s. Einstein's theory of relativity
explains this speed by a phenomenon known as the speed at
the end of time. In other words, this speed is
2025-02-10 20:48:31,209 - INFO - Round 20 of 20.
2025-02-10 20:48:31,869 - INFO - Generated 91 tokens in 0.66 seconds (137.96 tokens/sec)
2025-02-10 20:48:31,869 - INFO - Output:
Einstein's Theory of Relativity states that the speed of
light in a vacuum is simply the speed of the electrons in
that vacuum, since light has a speed. Since the speed of
light in a vacuum is equal to the speed of the electrons in
a solid, the light from this source has a speed of
approximately 1/299,792 m/s. Einstein's theory of relativity
explains this speed by a phenomenon known as the speed at
the end of time. In other words, this speed is
2025-02-10 20:48:31,869 - INFO - Run details saved to gpt2-rates-2025-02-10-20-48-31-869451-torch-compile-reduce-overhead-py313t.json.
torch.__init__: Ignoring unsupported torch.compile() with no GIL unsupported
torch._dynamo.eval_frame: Ignoring unsupported torch.compile() with no GIL unsupported
torch.__init__: Ignoring unsupported torch.compile() with no GIL unsupported
torch._dynamo.eval_frame: Ignoring unsupported torch.compile() with no GIL unsupported
real 0m20.138s
user 0m23.350s
sys 0m1.425s
Exception ignored in: <_io.BufferedWriter name=41>
BrokenPipeError: [Errno 32] Broken pipe
2025-02-10 20:48:38,069 - INFO - Loaded /mnt/raid1/trent/src/parallelopedia/data/model_19072.pt checkpoint in 0.481 seconds.
2025-02-10 20:48:38,076 - INFO - Initialized GPT model in 0.006 seconds.
2025-02-10 20:48:38,305 - INFO - Loaded model weights in 0.228 seconds.
<frozen importlib._bootstrap>:488: RuntimeWarning: The global interpreter lock (GIL) has been enabled to load module 'triton._C.libtriton', which has not declared that it can run safely without the GIL. To override this behavior and keep the GIL disabled (at your own risk), run with PYTHON_GIL=0 or -Xgil=0.
2025-02-10 20:48:38,672 - INFO - Created GPT model in 0.602 seconds.
2025-02-10 20:48:38,756 - INFO - Moved model to cuda:3 in 0.085 seconds.
2025-02-10 20:48:38,756 - INFO - Loaded model from step 19072, val_loss 3.0519702434539795
2025-02-10 20:48:38,757 - INFO - Loaded gpt2 on cuda:3 in 1.169 seconds.
2025-02-10 20:48:38,759 - INFO - torch.compiled model in 0.002 seconds.
2025-02-10 20:48:38,759 - INFO - Round 1 of 20.
2025-02-10 20:48:39,584 - INFO - Generated 91 tokens in 0.82 seconds (110.43 tokens/sec)
2025-02-10 20:48:39,584 - INFO - Output:
Einstein's Theory of Relativity states that the speed of
light in a vacuum is simply the speed of the electrons in
that vacuum, since light has a speed. Since the speed of
light in a vacuum is equal to the speed of the electrons in
a solid, the light from this source has a speed of
approximately 1/299,792 m/s. Einstein's theory of relativity
explains this speed by a phenomenon known as the speed at
the end of time. In other words, this speed is
2025-02-10 20:48:39,584 - INFO - Round 2 of 20.
2025-02-10 20:48:40,223 - INFO - Generated 91 tokens in 0.64 seconds (142.66 tokens/sec)
2025-02-10 20:48:40,223 - INFO - Output:
Einstein's Theory of Relativity states that the speed of
light in a vacuum is simply the speed of the electrons in
that vacuum, since light has a speed. Since the speed of
light in a vacuum is equal to the speed of the electrons in
a solid, the light from this source has a speed of
approximately 1/299,792 m/s. Einstein's theory of relativity
explains this speed by a phenomenon known as the speed at
the end of time. In other words, this speed is
2025-02-10 20:48:40,223 - INFO - Round 3 of 20.
2025-02-10 20:48:40,863 - INFO - Generated 91 tokens in 0.64 seconds (142.18 tokens/sec)
2025-02-10 20:48:40,864 - INFO - Output:
Einstein's Theory of Relativity states that the speed of
light in a vacuum is simply the speed of the electrons in
that vacuum, since light has a speed. Since the speed of
light in a vacuum is equal to the speed of the electrons in
a solid, the light from this source has a speed of
approximately 1/299,792 m/s. Einstein's theory of relativity
explains this speed by a phenomenon known as the speed at
the end of time. In other words, this speed is
2025-02-10 20:48:40,864 - INFO - Round 4 of 20.
2025-02-10 20:48:41,501 - INFO - Generated 91 tokens in 0.64 seconds (142.76 tokens/sec)
2025-02-10 20:48:41,502 - INFO - Output:
Einstein's Theory of Relativity states that the speed of
light in a vacuum is simply the speed of the electrons in
that vacuum, since light has a speed. Since the speed of
light in a vacuum is equal to the speed of the electrons in
a solid, the light from this source has a speed of
approximately 1/299,792 m/s. Einstein's theory of relativity
explains this speed by a phenomenon known as the speed at
the end of time. In other words, this speed is
2025-02-10 20:48:41,502 - INFO - Round 5 of 20.
2025-02-10 20:48:42,140 - INFO - Generated 91 tokens in 0.64 seconds (142.55 tokens/sec)
2025-02-10 20:48:42,141 - INFO - Output:
Einstein's Theory of Relativity states that the speed of
light in a vacuum is simply the speed of the electrons in
that vacuum, since light has a speed. Since the speed of
light in a vacuum is equal to the speed of the electrons in
a solid, the light from this source has a speed of
approximately 1/299,792 m/s. Einstein's theory of relativity
explains this speed by a phenomenon known as the speed at
the end of time. In other words, this speed is
2025-02-10 20:48:42,141 - INFO - Round 6 of 20.
2025-02-10 20:48:42,779 - INFO - Generated 91 tokens in 0.64 seconds (142.60 tokens/sec)
2025-02-10 20:48:42,779 - INFO - Output:
Einstein's Theory of Relativity states that the speed of
light in a vacuum is simply the speed of the electrons in
that vacuum, since light has a speed. Since the speed of
light in a vacuum is equal to the speed of the electrons in
a solid, the light from this source has a speed of
approximately 1/299,792 m/s. Einstein's theory of relativity
explains this speed by a phenomenon known as the speed at
the end of time. In other words, this speed is
2025-02-10 20:48:42,779 - INFO - Round 7 of 20.
2025-02-10 20:48:43,416 - INFO - Generated 91 tokens in 0.64 seconds (142.91 tokens/sec)
2025-02-10 20:48:43,417 - INFO - Output:
Einstein's Theory of Relativity states that the speed of
light in a vacuum is simply the speed of the electrons in
that vacuum, since light has a speed. Since the speed of
light in a vacuum is equal to the speed of the electrons in
a solid, the light from this source has a speed of
approximately 1/299,792 m/s. Einstein's theory of relativity
explains this speed by a phenomenon known as the speed at
the end of time. In other words, this speed is
2025-02-10 20:48:43,417 - INFO - Round 8 of 20.
2025-02-10 20:48:44,058 - INFO - Generated 91 tokens in 0.64 seconds (141.92 tokens/sec)
2025-02-10 20:48:44,059 - INFO - Output:
Einstein's Theory of Relativity states that the speed of
light in a vacuum is simply the speed of the electrons in
that vacuum, since light has a speed. Since the speed of
light in a vacuum is equal to the speed of the electrons in
a solid, the light from this source has a speed of
approximately 1/299,792 m/s. Einstein's theory of relativity
explains this speed by a phenomenon known as the speed at
the end of time. In other words, this speed is
2025-02-10 20:48:44,059 - INFO - Round 9 of 20.
2025-02-10 20:48:44,700 - INFO - Generated 91 tokens in 0.64 seconds (141.97 tokens/sec)
2025-02-10 20:48:44,700 - INFO - Output:
Einstein's Theory of Relativity states that the speed of
light in a vacuum is simply the speed of the electrons in
that vacuum, since light has a speed. Since the speed of
light in a vacuum is equal to the speed of the electrons in
a solid, the light from this source has a speed of
approximately 1/299,792 m/s. Einstein's theory of relativity
explains this speed by a phenomenon known as the speed at
the end of time. In other words, this speed is
2025-02-10 20:48:44,700 - INFO - Round 10 of 20.
2025-02-10 20:48:45,339 - INFO - Generated 91 tokens in 0.64 seconds (142.54 tokens/sec)
2025-02-10 20:48:45,339 - INFO - Output:
Einstein's Theory of Relativity states that the speed of
light in a vacuum is simply the speed of the electrons in
that vacuum, since light has a speed. Since the speed of
light in a vacuum is equal to the speed of the electrons in
a solid, the light from this source has a speed of
approximately 1/299,792 m/s. Einstein's theory of relativity
explains this speed by a phenomenon known as the speed at
the end of time. In other words, this speed is
2025-02-10 20:48:45,339 - INFO - Round 11 of 20.
2025-02-10 20:48:45,977 - INFO - Generated 91 tokens in 0.64 seconds (142.78 tokens/sec)
2025-02-10 20:48:45,977 - INFO - Output:
Einstein's Theory of Relativity states that the speed of
light in a vacuum is simply the speed of the electrons in
that vacuum, since light has a speed. Since the speed of
light in a vacuum is equal to the speed of the electrons in
a solid, the light from this source has a speed of
approximately 1/299,792 m/s. Einstein's theory of relativity
explains this speed by a phenomenon known as the speed at
the end of time. In other words, this speed is
2025-02-10 20:48:45,977 - INFO - Round 12 of 20.
2025-02-10 20:48:46,617 - INFO - Generated 91 tokens in 0.64 seconds (142.24 tokens/sec)
2025-02-10 20:48:46,618 - INFO - Output:
Einstein's Theory of Relativity states that the speed of
light in a vacuum is simply the speed of the electrons in
that vacuum, since light has a speed. Since the speed of
light in a vacuum is equal to the speed of the electrons in
a solid, the light from this source has a speed of
approximately 1/299,792 m/s. Einstein's theory of relativity
explains this speed by a phenomenon known as the speed at
the end of time. In other words, this speed is
2025-02-10 20:48:46,618 - INFO - Round 13 of 20.
2025-02-10 20:48:47,264 - INFO - Generated 91 tokens in 0.65 seconds (140.87 tokens/sec)
2025-02-10 20:48:47,264 - INFO - Output:
Einstein's Theory of Relativity states that the speed of
light in a vacuum is simply the speed of the electrons in
that vacuum, since light has a speed. Since the speed of
light in a vacuum is equal to the speed of the electrons in
a solid, the light from this source has a speed of
approximately 1/299,792 m/s. Einstein's theory of relativity
explains this speed by a phenomenon known as the speed at
the end of time. In other words, this speed is
2025-02-10 20:48:47,265 - INFO - Round 14 of 20.
2025-02-10 20:48:47,912 - INFO - Generated 91 tokens in 0.65 seconds (140.53 tokens/sec)
2025-02-10 20:48:47,913 - INFO - Output:
Einstein's Theory of Relativity states that the speed of
light in a vacuum is simply the speed of the electrons in
that vacuum, since light has a speed. Since the speed of
light in a vacuum is equal to the speed of the electrons in
a solid, the light from this source has a speed of
approximately 1/299,792 m/s. Einstein's theory of relativity
explains this speed by a phenomenon known as the speed at
the end of time. In other words, this speed is
2025-02-10 20:48:47,913 - INFO - Round 15 of 20.
2025-02-10 20:48:48,561 - INFO - Generated 91 tokens in 0.65 seconds (140.36 tokens/sec)
2025-02-10 20:48:48,562 - INFO - Output:
Einstein's Theory of Relativity states that the speed of
light in a vacuum is simply the speed of the electrons in
that vacuum, since light has a speed. Since the speed of
light in a vacuum is equal to the speed of the electrons in
a solid, the light from this source has a speed of
approximately 1/299,792 m/s. Einstein's theory of relativity
explains this speed by a phenomenon known as the speed at
the end of time. In other words, this speed is
2025-02-10 20:48:48,562 - INFO - Round 16 of 20.
2025-02-10 20:48:49,185 - INFO - Generated 91 tokens in 0.62 seconds (146.20 tokens/sec)
2025-02-10 20:48:49,185 - INFO - Output:
Einstein's Theory of Relativity states that the speed of
light in a vacuum is simply the speed of the electrons in
that vacuum, since light has a speed. Since the speed of
light in a vacuum is equal to the speed of the electrons in
a solid, the light from this source has a speed of
approximately 1/299,792 m/s. Einstein's theory of relativity
explains this speed by a phenomenon known as the speed at
the end of time. In other words, this speed is
2025-02-10 20:48:49,185 - INFO - Round 17 of 20.
2025-02-10 20:48:49,805 - INFO - Generated 91 tokens in 0.62 seconds (146.85 tokens/sec)
2025-02-10 20:48:49,805 - INFO - Output:
Einstein's Theory of Relativity states that the speed of
light in a vacuum is simply the speed of the electrons in
that vacuum, since light has a speed. Since the speed of
light in a vacuum is equal to the speed of the electrons in
a solid, the light from this source has a speed of
approximately 1/299,792 m/s. Einstein's theory of relativity
explains this speed by a phenomenon known as the speed at
the end of time. In other words, this speed is
2025-02-10 20:48:49,805 - INFO - Round 18 of 20.
2025-02-10 20:48:50,426 - INFO - Generated 91 tokens in 0.62 seconds (146.54 tokens/sec)
2025-02-10 20:48:50,427 - INFO - Output:
Einstein's Theory of Relativity states that the speed of
light in a vacuum is simply the speed of the electrons in
that vacuum, since light has a speed. Since the speed of
light in a vacuum is equal to the speed of the electrons in
a solid, the light from this source has a speed of
approximately 1/299,792 m/s. Einstein's theory of relativity
explains this speed by a phenomenon known as the speed at
the end of time. In other words, this speed is
2025-02-10 20:48:50,427 - INFO - Round 19 of 20.
2025-02-10 20:48:51,048 - INFO - Generated 91 tokens in 0.62 seconds (146.67 tokens/sec)
2025-02-10 20:48:51,048 - INFO - Output:
Einstein's Theory of Relativity states that the speed of
light in a vacuum is simply the speed of the electrons in
that vacuum, since light has a speed. Since the speed of
light in a vacuum is equal to the speed of the electrons in
a solid, the light from this source has a speed of
approximately 1/299,792 m/s. Einstein's theory of relativity
explains this speed by a phenomenon known as the speed at
the end of time. In other words, this speed is
2025-02-10 20:48:51,048 - INFO - Round 20 of 20.
2025-02-10 20:48:51,667 - INFO - Generated 91 tokens in 0.62 seconds (146.98 tokens/sec)
2025-02-10 20:48:51,668 - INFO - Output:
Einstein's Theory of Relativity states that the speed of
light in a vacuum is simply the speed of the electrons in
that vacuum, since light has a speed. Since the speed of
light in a vacuum is equal to the speed of the electrons in
a solid, the light from this source has a speed of
approximately 1/299,792 m/s. Einstein's theory of relativity
explains this speed by a phenomenon known as the speed at
the end of time. In other words, this speed is
2025-02-10 20:48:51,668 - INFO - Run details saved to gpt2-rates-2025-02-10-20-48-51-668280-torch-compile-reduce-overhead-fullgraph-py313t.json.
torch.__init__: Ignoring unsupported torch.compile() with no GIL unsupported
torch._dynamo.eval_frame: Ignoring unsupported torch.compile() with no GIL unsupported
torch.__init__: Ignoring unsupported torch.compile() with no GIL unsupported
torch._dynamo.eval_frame: Ignoring unsupported torch.compile() with no GIL unsupported
real 0m19.806s
user 0m23.067s
sys 0m1.336s
Exception ignored in: <_io.BufferedWriter name=41>
BrokenPipeError: [Errno 32] Broken pipe
2025-02-10 20:48:57,852 - INFO - Loaded /mnt/raid1/trent/src/parallelopedia/data/model_19072.pt checkpoint in 0.472 seconds.
2025-02-10 20:48:57,859 - INFO - Initialized GPT model in 0.007 seconds.
2025-02-10 20:48:58,087 - INFO - Loaded model weights in 0.228 seconds.
<frozen importlib._bootstrap>:488: RuntimeWarning: The global interpreter lock (GIL) has been enabled to load module 'triton._C.libtriton', which has not declared that it can run safely without the GIL. To override this behavior and keep the GIL disabled (at your own risk), run with PYTHON_GIL=0 or -Xgil=0.
2025-02-10 20:48:58,455 - INFO - Created GPT model in 0.603 seconds.
2025-02-10 20:48:58,540 - INFO - Moved model to cuda:3 in 0.085 seconds.
2025-02-10 20:48:58,540 - INFO - Loaded model from step 19072, val_loss 3.0519702434539795
2025-02-10 20:48:58,541 - INFO - Loaded gpt2 on cuda:3 in 1.161 seconds.
2025-02-10 20:48:58,543 - INFO - torch.compiled model in 0.003 seconds.
2025-02-10 20:48:58,543 - INFO - Round 1 of 20.
2025-02-10 20:48:59,366 - INFO - Generated 91 tokens in 0.82 seconds (110.79 tokens/sec)
2025-02-10 20:48:59,366 - INFO - Output:
Einstein's Theory of Relativity states that the speed of
light in a vacuum is simply the speed of the electrons in
that vacuum, since light has a speed. Since the speed of
light in a vacuum is equal to the speed of the electrons in
a solid, the light from this source has a speed of
approximately 1/299,792 m/s. Einstein's theory of relativity
explains this speed by a phenomenon known as the speed at
the end of time. In other words, this speed is
2025-02-10 20:48:59,366 - INFO - Round 2 of 20.
2025-02-10 20:49:00,019 - INFO - Generated 91 tokens in 0.65 seconds (139.51 tokens/sec)
2025-02-10 20:49:00,019 - INFO - Output:
Einstein's Theory of Relativity states that the speed of
light in a vacuum is simply the speed of the electrons in
that vacuum, since light has a speed. Since the speed of
light in a vacuum is equal to the speed of the electrons in
a solid, the light from this source has a speed of
approximately 1/299,792 m/s. Einstein's theory of relativity
explains this speed by a phenomenon known as the speed at
the end of time. In other words, this speed is
2025-02-10 20:49:00,019 - INFO - Round 3 of 20.
2025-02-10 20:49:00,706 - INFO - Generated 91 tokens in 0.69 seconds (132.47 tokens/sec)
2025-02-10 20:49:00,707 - INFO - Output:
Einstein's Theory of Relativity states that the speed of
light in a vacuum is simply the speed of the electrons in
that vacuum, since light has a speed. Since the speed of
light in a vacuum is equal to the speed of the electrons in
a solid, the light from this source has a speed of
approximately 1/299,792 m/s. Einstein's theory of relativity
explains this speed by a phenomenon known as the speed at
the end of time. In other words, this speed is
2025-02-10 20:49:00,707 - INFO - Round 4 of 20.
2025-02-10 20:49:01,327 - INFO - Generated 91 tokens in 0.62 seconds (146.66 tokens/sec)
2025-02-10 20:49:01,328 - INFO - Output:
Einstein's Theory of Relativity states that the speed of
light in a vacuum is simply the speed of the electrons in
that vacuum, since light has a speed. Since the speed of
light in a vacuum is equal to the speed of the electrons in
a solid, the light from this source has a speed of
approximately 1/299,792 m/s. Einstein's theory of relativity
explains this speed by a phenomenon known as the speed at
the end of time. In other words, this speed is
2025-02-10 20:49:01,328 - INFO - Round 5 of 20.
2025-02-10 20:49:01,950 - INFO - Generated 91 tokens in 0.62 seconds (146.40 tokens/sec)
2025-02-10 20:49:01,950 - INFO - Output:
Einstein's Theory of Relativity states that the speed of
light in a vacuum is simply the speed of the electrons in
that vacuum, since light has a speed. Since the speed of
light in a vacuum is equal to the speed of the electrons in
a solid, the light from this source has a speed of
approximately 1/299,792 m/s. Einstein's theory of relativity
explains this speed by a phenomenon known as the speed at
the end of time. In other words, this speed is
2025-02-10 20:49:01,950 - INFO - Round 6 of 20.
2025-02-10 20:49:02,571 - INFO - Generated 91 tokens in 0.62 seconds (146.62 tokens/sec)
2025-02-10 20:49:02,571 - INFO - Output:
Einstein's Theory of Relativity states that the speed of
light in a vacuum is simply the speed of the electrons in
that vacuum, since light has a speed. Since the speed of
light in a vacuum is equal to the speed of the electrons in
a solid, the light from this source has a speed of
approximately 1/299,792 m/s. Einstein's theory of relativity
explains this speed by a phenomenon known as the speed at
the end of time. In other words, this speed is
2025-02-10 20:49:02,571 - INFO - Round 7 of 20.
2025-02-10 20:49:03,193 - INFO - Generated 91 tokens in 0.62 seconds (146.54 tokens/sec)
2025-02-10 20:49:03,193 - INFO - Output:
Einstein's Theory of Relativity states that the speed of
light in a vacuum is simply the speed of the electrons in
that vacuum, since light has a speed. Since the speed of
light in a vacuum is equal to the speed of the electrons in
a solid, the light from this source has a speed of
approximately 1/299,792 m/s. Einstein's theory of relativity
explains this speed by a phenomenon known as the speed at
the end of time. In other words, this speed is
2025-02-10 20:49:03,193 - INFO - Round 8 of 20.
2025-02-10 20:49:03,816 - INFO - Generated 91 tokens in 0.62 seconds (146.13 tokens/sec)
2025-02-10 20:49:03,816 - INFO - Output:
Einstein's Theory of Relativity states that the speed of
light in a vacuum is simply the speed of the electrons in
that vacuum, since light has a speed. Since the speed of
light in a vacuum is equal to the speed of the electrons in
a solid, the light from this source has a speed of
approximately 1/299,792 m/s. Einstein's theory of relativity
explains this speed by a phenomenon known as the speed at
the end of time. In other words, this speed is
2025-02-10 20:49:03,816 - INFO - Round 9 of 20.
2025-02-10 20:49:04,444 - INFO - Generated 91 tokens in 0.63 seconds (145.02 tokens/sec)
2025-02-10 20:49:04,444 - INFO - Output:
Einstein's Theory of Relativity states that the speed of
light in a vacuum is simply the speed of the electrons in
that vacuum, since light has a speed. Since the speed of
light in a vacuum is equal to the speed of the electrons in
a solid, the light from this source has a speed of
approximately 1/299,792 m/s. Einstein's theory of relativity
explains this speed by a phenomenon known as the speed at
the end of time. In other words, this speed is
2025-02-10 20:49:04,444 - INFO - Round 10 of 20.
2025-02-10 20:49:05,066 - INFO - Generated 91 tokens in 0.62 seconds (146.47 tokens/sec)
2025-02-10 20:49:05,066 - INFO - Output:
Einstein's Theory of Relativity states that the speed of
light in a vacuum is simply the speed of the electrons in
that vacuum, since light has a speed. Since the speed of
light in a vacuum is equal to the speed of the electrons in
a solid, the light from this source has a speed of
approximately 1/299,792 m/s. Einstein's theory of relativity
explains this speed by a phenomenon known as the speed at
the end of time. In other words, this speed is
2025-02-10 20:49:05,066 - INFO - Round 11 of 20.
2025-02-10 20:49:05,688 - INFO - Generated 91 tokens in 0.62 seconds (146.45 tokens/sec)
2025-02-10 20:49:05,688 - INFO - Output:
Einstein's Theory of Relativity states that the speed of
light in a vacuum is simply the speed of the electrons in
that vacuum, since light has a speed. Since the speed of
light in a vacuum is equal to the speed of the electrons in
a solid, the light from this source has a speed of
approximately 1/299,792 m/s. Einstein's theory of relativity
explains this speed by a phenomenon known as the speed at
the end of time. In other words, this speed is
2025-02-10 20:49:05,688 - INFO - Round 12 of 20.
2025-02-10 20:49:06,310 - INFO - Generated 91 tokens in 0.62 seconds (146.37 tokens/sec)
2025-02-10 20:49:06,311 - INFO - Output:
Einstein's Theory of Relativity states that the speed of
light in a vacuum is simply the speed of the electrons in
that vacuum, since light has a speed. Since the speed of
light in a vacuum is equal to the speed of the electrons in
a solid, the light from this source has a speed of
approximately 1/299,792 m/s. Einstein's theory of relativity
explains this speed by a phenomenon known as the speed at
the end of time. In other words, this speed is
2025-02-10 20:49:06,311 - INFO - Round 13 of 20.
2025-02-10 20:49:06,933 - INFO - Generated 91 tokens in 0.62 seconds (146.27 tokens/sec)
2025-02-10 20:49:06,933 - INFO - Output:
Einstein's Theory of Relativity states that the speed of
light in a vacuum is simply the speed of the electrons in
that vacuum, since light has a speed. Since the speed of
light in a vacuum is equal to the speed of the electrons in
a solid, the light from this source has a speed of
approximately 1/299,792 m/s. Einstein's theory of relativity
explains this speed by a phenomenon known as the speed at
the end of time. In other words, this speed is
2025-02-10 20:49:06,933 - INFO - Round 14 of 20.
2025-02-10 20:49:07,554 - INFO - Generated 91 tokens in 0.62 seconds (146.56 tokens/sec)
2025-02-10 20:49:07,555 - INFO - Output:
Einstein's Theory of Relativity states that the speed of
light in a vacuum is simply the speed of the electrons in
that vacuum, since light has a speed. Since the speed of
light in a vacuum is equal to the speed of the electrons in
a solid, the light from this source has a speed of
approximately 1/299,792 m/s. Einstein's theory of relativity
explains this speed by a phenomenon known as the speed at
the end of time. In other words, this speed is
2025-02-10 20:49:07,555 - INFO - Round 15 of 20.
2025-02-10 20:49:08,176 - INFO - Generated 91 tokens in 0.62 seconds (146.45 tokens/sec)
2025-02-10 20:49:08,177 - INFO - Output:
Einstein's Theory of Relativity states that the speed of
light in a vacuum is simply the speed of the electrons in
that vacuum, since light has a speed. Since the speed of
light in a vacuum is equal to the speed of the electrons in
a solid, the light from this source has a speed of
approximately 1/299,792 m/s. Einstein's theory of relativity
explains this speed by a phenomenon known as the speed at
the end of time. In other words, this speed is
2025-02-10 20:49:08,177 - INFO - Round 16 of 20.
2025-02-10 20:49:08,799 - INFO - Generated 91 tokens in 0.62 seconds (146.39 tokens/sec)
2025-02-10 20:49:08,799 - INFO - Output:
Einstein's Theory of Relativity states that the speed of
light in a vacuum is simply the speed of the electrons in
that vacuum, since light has a speed. Since the speed of
light in a vacuum is equal to the speed of the electrons in
a solid, the light from this source has a speed of
approximately 1/299,792 m/s. Einstein's theory of relativity
explains this speed by a phenomenon known as the speed at
the end of time. In other words, this speed is
2025-02-10 20:49:08,799 - INFO - Round 17 of 20.
2025-02-10 20:49:09,420 - INFO - Generated 91 tokens in 0.62 seconds (146.49 tokens/sec)
2025-02-10 20:49:09,421 - INFO - Output:
Einstein's Theory of Relativity states that the speed of
light in a vacuum is simply the speed of the electrons in
that vacuum, since light has a speed. Since the speed of
light in a vacuum is equal to the speed of the electrons in
a solid, the light from this source has a speed of
approximately 1/299,792 m/s. Einstein's theory of relativity
explains this speed by a phenomenon known as the speed at
the end of time. In other words, this speed is
2025-02-10 20:49:09,421 - INFO - Round 18 of 20.
2025-02-10 20:49:10,043 - INFO - Generated 91 tokens in 0.62 seconds (146.24 tokens/sec)
2025-02-10 20:49:10,044 - INFO - Output:
Einstein's Theory of Relativity states that the speed of
light in a vacuum is simply the speed of the electrons in
that vacuum, since light has a speed. Since the speed of
light in a vacuum is equal to the speed of the electrons in
a solid, the light from this source has a speed of
approximately 1/299,792 m/s. Einstein's theory of relativity
explains this speed by a phenomenon known as the speed at
the end of time. In other words, this speed is
2025-02-10 20:49:10,044 - INFO - Round 19 of 20.
2025-02-10 20:49:10,665 - INFO - Generated 91 tokens in 0.62 seconds (146.62 tokens/sec)
2025-02-10 20:49:10,665 - INFO - Output:
Einstein's Theory of Relativity states that the speed of
light in a vacuum is simply the speed of the electrons in
that vacuum, since light has a speed. Since the speed of
light in a vacuum is equal to the speed of the electrons in
a solid, the light from this source has a speed of
approximately 1/299,792 m/s. Einstein's theory of relativity
explains this speed by a phenomenon known as the speed at
the end of time. In other words, this speed is
2025-02-10 20:49:10,665 - INFO - Round 20 of 20.
2025-02-10 20:49:11,286 - INFO - Generated 91 tokens in 0.62 seconds (146.54 tokens/sec)
2025-02-10 20:49:11,286 - INFO - Output:
Einstein's Theory of Relativity states that the speed of
light in a vacuum is simply the speed of the electrons in
that vacuum, since light has a speed. Since the speed of
light in a vacuum is equal to the speed of the electrons in
a solid, the light from this source has a speed of
approximately 1/299,792 m/s. Einstein's theory of relativity
explains this speed by a phenomenon known as the speed at
the end of time. In other words, this speed is
2025-02-10 20:49:11,287 - INFO - Run details saved to gpt2-rates-2025-02-10-20-49-11-287012-torch-compile-reduce-overhead-fullgraph-py313t.json.
torch.__init__: Ignoring unsupported torch.compile() with no GIL unsupported
torch._dynamo.eval_frame: Ignoring unsupported torch.compile() with no GIL unsupported
torch.__init__: Ignoring unsupported torch.compile() with no GIL unsupported
torch._dynamo.eval_frame: Ignoring unsupported torch.compile() with no GIL unsupported
real 0m19.626s
user 0m22.831s
sys 0m1.406s
Exception ignored in: <_io.BufferedWriter name=41>
BrokenPipeError: [Errno 32] Broken pipe
2025-02-10 20:49:17,458 - INFO - Loaded /mnt/raid1/trent/src/parallelopedia/data/model_19072.pt checkpoint in 0.491 seconds.
2025-02-10 20:49:17,465 - INFO - Initialized GPT model in 0.006 seconds.
2025-02-10 20:49:17,704 - INFO - Loaded model weights in 0.239 seconds.
<frozen importlib._bootstrap>:488: RuntimeWarning: The global interpreter lock (GIL) has been enabled to load module 'triton._C.libtriton', which has not declared that it can run safely without the GIL. To override this behavior and keep the GIL disabled (at your own risk), run with PYTHON_GIL=0 or -Xgil=0.
2025-02-10 20:49:18,069 - INFO - Created GPT model in 0.611 seconds.
2025-02-10 20:49:18,153 - INFO - Moved model to cuda:3 in 0.084 seconds.
2025-02-10 20:49:18,153 - INFO - Loaded model from step 19072, val_loss 3.0519702434539795
2025-02-10 20:49:18,153 - INFO - Loaded gpt2 on cuda:3 in 1.187 seconds.
2025-02-10 20:49:18,157 - INFO - torch.compiled model in 0.003 seconds.
2025-02-10 20:49:18,157 - INFO - Round 1 of 20.
2025-02-10 20:49:18,973 - INFO - Generated 91 tokens in 0.82 seconds (111.60 tokens/sec)
2025-02-10 20:49:18,973 - INFO - Output:
Einstein's Theory of Relativity states that the speed of
light in a vacuum is simply the speed of the electrons in
that vacuum, since light has a speed. Since the speed of
light in a vacuum is equal to the speed of the electrons in
a solid, the light from this source has a speed of
approximately 1/299,792 m/s. Einstein's theory of relativity
explains this speed by a phenomenon known as the speed at
the end of time. In other words, this speed is
2025-02-10 20:49:18,973 - INFO - Round 2 of 20.
2025-02-10 20:49:19,621 - INFO - Generated 91 tokens in 0.65 seconds (140.58 tokens/sec)
2025-02-10 20:49:19,621 - INFO - Output:
Einstein's Theory of Relativity states that the speed of
light in a vacuum is simply the speed of the electrons in
that vacuum, since light has a speed. Since the speed of
light in a vacuum is equal to the speed of the electrons in
a solid, the light from this source has a speed of
approximately 1/299,792 m/s. Einstein's theory of relativity
explains this speed by a phenomenon known as the speed at
the end of time. In other words, this speed is
2025-02-10 20:49:19,621 - INFO - Round 3 of 20.
2025-02-10 20:49:20,266 - INFO - Generated 91 tokens in 0.64 seconds (141.26 tokens/sec)
2025-02-10 20:49:20,266 - INFO - Output:
Einstein's Theory of Relativity states that the speed of
light in a vacuum is simply the speed of the electrons in
that vacuum, since light has a speed. Since the speed of
light in a vacuum is equal to the speed of the electrons in
a solid, the light from this source has a speed of
approximately 1/299,792 m/s. Einstein's theory of relativity
explains this speed by a phenomenon known as the speed at
the end of time. In other words, this speed is
2025-02-10 20:49:20,266 - INFO - Round 4 of 20.
2025-02-10 20:49:20,911 - INFO - Generated 91 tokens in 0.64 seconds (141.24 tokens/sec)
2025-02-10 20:49:20,911 - INFO - Output:
Einstein's Theory of Relativity states that the speed of
light in a vacuum is simply the speed of the electrons in
that vacuum, since light has a speed. Since the speed of
light in a vacuum is equal to the speed of the electrons in
a solid, the light from this source has a speed of
approximately 1/299,792 m/s. Einstein's theory of relativity
explains this speed by a phenomenon known as the speed at
the end of time. In other words, this speed is
2025-02-10 20:49:20,911 - INFO - Round 5 of 20.
2025-02-10 20:49:21,555 - INFO - Generated 91 tokens in 0.64 seconds (141.46 tokens/sec)
2025-02-10 20:49:21,555 - INFO - Output:
Einstein's Theory of Relativity states that the speed of
light in a vacuum is simply the speed of the electrons in
that vacuum, since light has a speed. Since the speed of
light in a vacuum is equal to the speed of the electrons in
a solid, the light from this source has a speed of
approximately 1/299,792 m/s. Einstein's theory of relativity
explains this speed by a phenomenon known as the speed at
the end of time. In other words, this speed is
2025-02-10 20:49:21,555 - INFO - Round 6 of 20.
2025-02-10 20:49:22,199 - INFO - Generated 91 tokens in 0.64 seconds (141.27 tokens/sec)
2025-02-10 20:49:22,200 - INFO - Output:
Einstein's Theory of Relativity states that the speed of
light in a vacuum is simply the speed of the electrons in
that vacuum, since light has a speed. Since the speed of
light in a vacuum is equal to the speed of the electrons in
a solid, the light from this source has a speed of
approximately 1/299,792 m/s. Einstein's theory of relativity
explains this speed by a phenomenon known as the speed at
the end of time. In other words, this speed is
2025-02-10 20:49:22,200 - INFO - Round 7 of 20.
2025-02-10 20:49:22,846 - INFO - Generated 91 tokens in 0.65 seconds (140.98 tokens/sec)
2025-02-10 20:49:22,846 - INFO - Output:
Einstein's Theory of Relativity states that the speed of
light in a vacuum is simply the speed of the electrons in
that vacuum, since light has a speed. Since the speed of
light in a vacuum is equal to the speed of the electrons in
a solid, the light from this source has a speed of
approximately 1/299,792 m/s. Einstein's theory of relativity
explains this speed by a phenomenon known as the speed at
the end of time. In other words, this speed is
2025-02-10 20:49:22,846 - INFO - Round 8 of 20.
2025-02-10 20:49:23,486 - INFO - Generated 91 tokens in 0.64 seconds (142.29 tokens/sec)
2025-02-10 20:49:23,487 - INFO - Output:
Einstein's Theory of Relativity states that the speed of
light in a vacuum is simply the speed of the electrons in
that vacuum, since light has a speed. Since the speed of
light in a vacuum is equal to the speed of the electrons in
a solid, the light from this source has a speed of
approximately 1/299,792 m/s. Einstein's theory of relativity
explains this speed by a phenomenon known as the speed at
the end of time. In other words, this speed is
2025-02-10 20:49:23,487 - INFO - Round 9 of 20.
2025-02-10 20:49:24,129 - INFO - Generated 91 tokens in 0.64 seconds (141.71 tokens/sec)
2025-02-10 20:49:24,130 - INFO - Output:
Einstein's Theory of Relativity states that the speed of
light in a vacuum is simply the speed of the electrons in
that vacuum, since light has a speed. Since the speed of
light in a vacuum is equal to the speed of the electrons in
a solid, the light from this source has a speed of
approximately 1/299,792 m/s. Einstein's theory of relativity
explains this speed by a phenomenon known as the speed at
the end of time. In other words, this speed is
2025-02-10 20:49:24,130 - INFO - Round 10 of 20.
2025-02-10 20:49:24,771 - INFO - Generated 91 tokens in 0.64 seconds (141.83 tokens/sec)
2025-02-10 20:49:24,772 - INFO - Output:
Einstein's Theory of Relativity states that the speed of
light in a vacuum is simply the speed of the electrons in
that vacuum, since light has a speed. Since the speed of
light in a vacuum is equal to the speed of the electrons in
a solid, the light from this source has a speed of
approximately 1/299,792 m/s. Einstein's theory of relativity
explains this speed by a phenomenon known as the speed at
the end of time. In other words, this speed is
2025-02-10 20:49:24,772 - INFO - Round 11 of 20.
2025-02-10 20:49:25,413 - INFO - Generated 91 tokens in 0.64 seconds (142.00 tokens/sec)
2025-02-10 20:49:25,413 - INFO - Output:
Einstein's Theory of Relativity states that the speed of
light in a vacuum is simply the speed of the electrons in
that vacuum, since light has a speed. Since the speed of
light in a vacuum is equal to the speed of the electrons in
a solid, the light from this source has a speed of
approximately 1/299,792 m/s. Einstein's theory of relativity
explains this speed by a phenomenon known as the speed at
the end of time. In other words, this speed is
2025-02-10 20:49:25,414 - INFO - Round 12 of 20.
2025-02-10 20:49:26,056 - INFO - Generated 91 tokens in 0.64 seconds (141.66 tokens/sec)
2025-02-10 20:49:26,056 - INFO - Output:
Einstein's Theory of Relativity states that the speed of
light in a vacuum is simply the speed of the electrons in
that vacuum, since light has a speed. Since the speed of
light in a vacuum is equal to the speed of the electrons in
a solid, the light from this source has a speed of
approximately 1/299,792 m/s. Einstein's theory of relativity
explains this speed by a phenomenon known as the speed at
the end of time. In other words, this speed is
2025-02-10 20:49:26,057 - INFO - Round 13 of 20.
2025-02-10 20:49:26,703 - INFO - Generated 91 tokens in 0.65 seconds (140.87 tokens/sec)
2025-02-10 20:49:26,703 - INFO - Output:
Einstein's Theory of Relativity states that the speed of
light in a vacuum is simply the speed of the electrons in
that vacuum, since light has a speed. Since the speed of
light in a vacuum is equal to the speed of the electrons in
a solid, the light from this source has a speed of
approximately 1/299,792 m/s. Einstein's theory of relativity
explains this speed by a phenomenon known as the speed at
the end of time. In other words, this speed is
2025-02-10 20:49:26,703 - INFO - Round 14 of 20.
2025-02-10 20:49:27,344 - INFO - Generated 91 tokens in 0.64 seconds (141.96 tokens/sec)
2025-02-10 20:49:27,345 - INFO - Output:
Einstein's Theory of Relativity states that the speed of
light in a vacuum is simply the speed of the electrons in
that vacuum, since light has a speed. Since the speed of
light in a vacuum is equal to the speed of the electrons in
a solid, the light from this source has a speed of
approximately 1/299,792 m/s. Einstein's theory of relativity
explains this speed by a phenomenon known as the speed at
the end of time. In other words, this speed is
2025-02-10 20:49:27,345 - INFO - Round 15 of 20.
2025-02-10 20:49:27,986 - INFO - Generated 91 tokens in 0.64 seconds (142.08 tokens/sec)
2025-02-10 20:49:27,986 - INFO - Output:
Einstein's Theory of Relativity states that the speed of
light in a vacuum is simply the speed of the electrons in
that vacuum, since light has a speed. Since the speed of
light in a vacuum is equal to the speed of the electrons in
a solid, the light from this source has a speed of
approximately 1/299,792 m/s. Einstein's theory of relativity
explains this speed by a phenomenon known as the speed at
the end of time. In other words, this speed is
2025-02-10 20:49:27,986 - INFO - Round 16 of 20.
2025-02-10 20:49:28,628 - INFO - Generated 91 tokens in 0.64 seconds (141.93 tokens/sec)
2025-02-10 20:49:28,628 - INFO - Output:
Einstein's Theory of Relativity states that the speed of
light in a vacuum is simply the speed of the electrons in
that vacuum, since light has a speed. Since the speed of
light in a vacuum is equal to the speed of the electrons in
a solid, the light from this source has a speed of
approximately 1/299,792 m/s. Einstein's theory of relativity
explains this speed by a phenomenon known as the speed at
the end of time. In other words, this speed is
2025-02-10 20:49:28,628 - INFO - Round 17 of 20.
2025-02-10 20:49:29,269 - INFO - Generated 91 tokens in 0.64 seconds (142.10 tokens/sec)
2025-02-10 20:49:29,269 - INFO - Output:
Einstein's Theory of Relativity states that the speed of
light in a vacuum is simply the speed of the electrons in
that vacuum, since light has a speed. Since the speed of
light in a vacuum is equal to the speed of the electrons in
a solid, the light from this source has a speed of
approximately 1/299,792 m/s. Einstein's theory of relativity
explains this speed by a phenomenon known as the speed at
the end of time. In other words, this speed is
2025-02-10 20:49:29,269 - INFO - Round 18 of 20.
2025-02-10 20:49:29,913 - INFO - Generated 91 tokens in 0.64 seconds (141.43 tokens/sec)
2025-02-10 20:49:29,913 - INFO - Output:
Einstein's Theory of Relativity states that the speed of
light in a vacuum is simply the speed of the electrons in
that vacuum, since light has a speed. Since the speed of
light in a vacuum is equal to the speed of the electrons in
a solid, the light from this source has a speed of
approximately 1/299,792 m/s. Einstein's theory of relativity
explains this speed by a phenomenon known as the speed at
the end of time. In other words, this speed is
2025-02-10 20:49:29,913 - INFO - Round 19 of 20.
2025-02-10 20:49:30,557 - INFO - Generated 91 tokens in 0.64 seconds (141.46 tokens/sec)
2025-02-10 20:49:30,557 - INFO - Output:
Einstein's Theory of Relativity states that the speed of
light in a vacuum is simply the speed of the electrons in
that vacuum, since light has a speed. Since the speed of
light in a vacuum is equal to the speed of the electrons in
a solid, the light from this source has a speed of
approximately 1/299,792 m/s. Einstein's theory of relativity
explains this speed by a phenomenon known as the speed at
the end of time. In other words, this speed is
2025-02-10 20:49:30,557 - INFO - Round 20 of 20.
2025-02-10 20:49:31,199 - INFO - Generated 91 tokens in 0.64 seconds (141.84 tokens/sec)
2025-02-10 20:49:31,199 - INFO - Output:
Einstein's Theory of Relativity states that the speed of
light in a vacuum is simply the speed of the electrons in
that vacuum, since light has a speed. Since the speed of
light in a vacuum is equal to the speed of the electrons in
a solid, the light from this source has a speed of
approximately 1/299,792 m/s. Einstein's theory of relativity
explains this speed by a phenomenon known as the speed at
the end of time. In other words, this speed is
2025-02-10 20:49:31,200 - INFO - Run details saved to gpt2-rates-2025-02-10-20-49-31-199651-torch-compile-max-autotune-py313t.json.
torch.__init__: Ignoring unsupported torch.compile() with no GIL unsupported
torch._dynamo.eval_frame: Ignoring unsupported torch.compile() with no GIL unsupported
torch.__init__: Ignoring unsupported torch.compile() with no GIL unsupported
torch._dynamo.eval_frame: Ignoring unsupported torch.compile() with no GIL unsupported
real 0m19.900s
user 0m23.112s
sys 0m1.409s
Exception ignored in: <_io.BufferedWriter name=41>
BrokenPipeError: [Errno 32] Broken pipe
2025-02-10 20:49:37,383 - INFO - Loaded /mnt/raid1/trent/src/parallelopedia/data/model_19072.pt checkpoint in 0.482 seconds.
2025-02-10 20:49:37,390 - INFO - Initialized GPT model in 0.006 seconds.
2025-02-10 20:49:37,613 - INFO - Loaded model weights in 0.223 seconds.
<frozen importlib._bootstrap>:488: RuntimeWarning: The global interpreter lock (GIL) has been enabled to load module 'triton._C.libtriton', which has not declared that it can run safely without the GIL. To override this behavior and keep the GIL disabled (at your own risk), run with PYTHON_GIL=0 or -Xgil=0.
2025-02-10 20:49:37,976 - INFO - Created GPT model in 0.592 seconds.
2025-02-10 20:49:38,058 - INFO - Moved model to cuda:3 in 0.082 seconds.
2025-02-10 20:49:38,058 - INFO - Loaded model from step 19072, val_loss 3.0519702434539795
2025-02-10 20:49:38,058 - INFO - Loaded gpt2 on cuda:3 in 1.157 seconds.
2025-02-10 20:49:38,061 - INFO - torch.compiled model in 0.002 seconds.
2025-02-10 20:49:38,061 - INFO - Round 1 of 20.
2025-02-10 20:49:38,896 - INFO - Generated 91 tokens in 0.83 seconds (109.09 tokens/sec)
2025-02-10 20:49:38,896 - INFO - Output:
Einstein's Theory of Relativity states that the speed of
light in a vacuum is simply the speed of the electrons in
that vacuum, since light has a speed. Since the speed of
light in a vacuum is equal to the speed of the electrons in
a solid, the light from this source has a speed of
approximately 1/299,792 m/s. Einstein's theory of relativity
explains this speed by a phenomenon known as the speed at
the end of time. In other words, this speed is
2025-02-10 20:49:38,896 - INFO - Round 2 of 20.
2025-02-10 20:49:39,552 - INFO - Generated 91 tokens in 0.66 seconds (138.68 tokens/sec)
2025-02-10 20:49:39,553 - INFO - Output:
Einstein's Theory of Relativity states that the speed of
light in a vacuum is simply the speed of the electrons in
that vacuum, since light has a speed. Since the speed of
light in a vacuum is equal to the speed of the electrons in
a solid, the light from this source has a speed of
approximately 1/299,792 m/s. Einstein's theory of relativity
explains this speed by a phenomenon known as the speed at
the end of time. In other words, this speed is
2025-02-10 20:49:39,553 - INFO - Round 3 of 20.
2025-02-10 20:49:40,199 - INFO - Generated 91 tokens in 0.65 seconds (140.90 tokens/sec)
2025-02-10 20:49:40,199 - INFO - Output:
Einstein's Theory of Relativity states that the speed of
light in a vacuum is simply the speed of the electrons in
that vacuum, since light has a speed. Since the speed of
light in a vacuum is equal to the speed of the electrons in
a solid, the light from this source has a speed of
approximately 1/299,792 m/s. Einstein's theory of relativity
explains this speed by a phenomenon known as the speed at
the end of time. In other words, this speed is
2025-02-10 20:49:40,199 - INFO - Round 4 of 20.
2025-02-10 20:49:40,851 - INFO - Generated 91 tokens in 0.65 seconds (139.61 tokens/sec)
2025-02-10 20:49:40,852 - INFO - Output:
Einstein's Theory of Relativity states that the speed of
light in a vacuum is simply the speed of the electrons in
that vacuum, since light has a speed. Since the speed of
light in a vacuum is equal to the speed of the electrons in
a solid, the light from this source has a speed of
approximately 1/299,792 m/s. Einstein's theory of relativity
explains this speed by a phenomenon known as the speed at
the end of time. In other words, this speed is
2025-02-10 20:49:40,852 - INFO - Round 5 of 20.
2025-02-10 20:49:41,496 - INFO - Generated 91 tokens in 0.64 seconds (141.24 tokens/sec)
2025-02-10 20:49:41,497 - INFO - Output:
Einstein's Theory of Relativity states that the speed of
light in a vacuum is simply the speed of the electrons in
that vacuum, since light has a speed. Since the speed of
light in a vacuum is equal to the speed of the electrons in
a solid, the light from this source has a speed of
approximately 1/299,792 m/s. Einstein's theory of relativity
explains this speed by a phenomenon known as the speed at
the end of time. In other words, this speed is
2025-02-10 20:49:41,497 - INFO - Round 6 of 20.
2025-02-10 20:49:42,143 - INFO - Generated 91 tokens in 0.65 seconds (140.79 tokens/sec)
2025-02-10 20:49:42,144 - INFO - Output:
Einstein's Theory of Relativity states that the speed of
light in a vacuum is simply the speed of the electrons in
that vacuum, since light has a speed. Since the speed of
light in a vacuum is equal to the speed of the electrons in
a solid, the light from this source has a speed of
approximately 1/299,792 m/s. Einstein's theory of relativity
explains this speed by a phenomenon known as the speed at
the end of time. In other words, this speed is
2025-02-10 20:49:42,144 - INFO - Round 7 of 20.
2025-02-10 20:49:42,794 - INFO - Generated 91 tokens in 0.65 seconds (139.98 tokens/sec)
2025-02-10 20:49:42,794 - INFO - Output:
Einstein's Theory of Relativity states that the speed of
light in a vacuum is simply the speed of the electrons in
that vacuum, since light has a speed. Since the speed of
light in a vacuum is equal to the speed of the electrons in
a solid, the light from this source has a speed of
approximately 1/299,792 m/s. Einstein's theory of relativity
explains this speed by a phenomenon known as the speed at
the end of time. In other words, this speed is
2025-02-10 20:49:42,795 - INFO - Round 8 of 20.
2025-02-10 20:49:43,442 - INFO - Generated 91 tokens in 0.65 seconds (140.59 tokens/sec)
2025-02-10 20:49:43,442 - INFO - Output:
Einstein's Theory of Relativity states that the speed of
light in a vacuum is simply the speed of the electrons in
that vacuum, since light has a speed. Since the speed of
light in a vacuum is equal to the speed of the electrons in
a solid, the light from this source has a speed of
approximately 1/299,792 m/s. Einstein's theory of relativity
explains this speed by a phenomenon known as the speed at
the end of time. In other words, this speed is
2025-02-10 20:49:43,442 - INFO - Round 9 of 20.
2025-02-10 20:49:44,088 - INFO - Generated 91 tokens in 0.65 seconds (141.07 tokens/sec)
2025-02-10 20:49:44,088 - INFO - Output:
Einstein's Theory of Relativity states that the speed of
light in a vacuum is simply the speed of the electrons in
that vacuum, since light has a speed. Since the speed of
light in a vacuum is equal to the speed of the electrons in
a solid, the light from this source has a speed of
approximately 1/299,792 m/s. Einstein's theory of relativity
explains this speed by a phenomenon known as the speed at
the end of time. In other words, this speed is
2025-02-10 20:49:44,088 - INFO - Round 10 of 20.
2025-02-10 20:49:44,738 - INFO - Generated 91 tokens in 0.65 seconds (140.10 tokens/sec)
2025-02-10 20:49:44,738 - INFO - Output:
Einstein's Theory of Relativity states that the speed of
light in a vacuum is simply the speed of the electrons in
that vacuum, since light has a speed. Since the speed of
light in a vacuum is equal to the speed of the electrons in
a solid, the light from this source has a speed of
approximately 1/299,792 m/s. Einstein's theory of relativity
explains this speed by a phenomenon known as the speed at
the end of time. In other words, this speed is
2025-02-10 20:49:44,738 - INFO - Round 11 of 20.
2025-02-10 20:49:45,382 - INFO - Generated 91 tokens in 0.64 seconds (141.34 tokens/sec)
2025-02-10 20:49:45,383 - INFO - Output:
Einstein's Theory of Relativity states that the speed of
light in a vacuum is simply the speed of the electrons in
that vacuum, since light has a speed. Since the speed of
light in a vacuum is equal to the speed of the electrons in
a solid, the light from this source has a speed of
approximately 1/299,792 m/s. Einstein's theory of relativity
explains this speed by a phenomenon known as the speed at
the end of time. In other words, this speed is
2025-02-10 20:49:45,383 - INFO - Round 12 of 20.
2025-02-10 20:49:46,026 - INFO - Generated 91 tokens in 0.64 seconds (141.47 tokens/sec)
2025-02-10 20:49:46,027 - INFO - Output:
Einstein's Theory of Relativity states that the speed of
light in a vacuum is simply the speed of the electrons in
that vacuum, since light has a speed. Since the speed of
light in a vacuum is equal to the speed of the electrons in
a solid, the light from this source has a speed of
approximately 1/299,792 m/s. Einstein's theory of relativity
explains this speed by a phenomenon known as the speed at
the end of time. In other words, this speed is
2025-02-10 20:49:46,027 - INFO - Round 13 of 20.
2025-02-10 20:49:46,695 - INFO - Generated 91 tokens in 0.67 seconds (136.23 tokens/sec)
2025-02-10 20:49:46,695 - INFO - Output:
Einstein's Theory of Relativity states that the speed of
light in a vacuum is simply the speed of the electrons in
that vacuum, since light has a speed. Since the speed of
light in a vacuum is equal to the speed of the electrons in
a solid, the light from this source has a speed of
approximately 1/299,792 m/s. Einstein's theory of relativity
explains this speed by a phenomenon known as the speed at
the end of time. In other words, this speed is
2025-02-10 20:49:46,695 - INFO - Round 14 of 20.
2025-02-10 20:49:47,339 - INFO - Generated 91 tokens in 0.64 seconds (141.40 tokens/sec)
2025-02-10 20:49:47,340 - INFO - Output:
Einstein's Theory of Relativity states that the speed of
light in a vacuum is simply the speed of the electrons in
that vacuum, since light has a speed. Since the speed of
light in a vacuum is equal to the speed of the electrons in
a solid, the light from this source has a speed of
approximately 1/299,792 m/s. Einstein's theory of relativity
explains this speed by a phenomenon known as the speed at
the end of time. In other words, this speed is
2025-02-10 20:49:47,340 - INFO - Round 15 of 20.
2025-02-10 20:49:47,988 - INFO - Generated 91 tokens in 0.65 seconds (140.35 tokens/sec)
2025-02-10 20:49:47,989 - INFO - Output:
Einstein's Theory of Relativity states that the speed of
light in a vacuum is simply the speed of the electrons in
that vacuum, since light has a speed. Since the speed of
light in a vacuum is equal to the speed of the electrons in
a solid, the light from this source has a speed of
approximately 1/299,792 m/s. Einstein's theory of relativity
explains this speed by a phenomenon known as the speed at
the end of time. In other words, this speed is
2025-02-10 20:49:47,989 - INFO - Round 16 of 20.
2025-02-10 20:49:48,649 - INFO - Generated 91 tokens in 0.66 seconds (137.84 tokens/sec)
2025-02-10 20:49:48,649 - INFO - Output:
Einstein's Theory of Relativity states that the speed of
light in a vacuum is simply the speed of the electrons in
that vacuum, since light has a speed. Since the speed of
light in a vacuum is equal to the speed of the electrons in
a solid, the light from this source has a speed of
approximately 1/299,792 m/s. Einstein's theory of relativity
explains this speed by a phenomenon known as the speed at
the end of time. In other words, this speed is
2025-02-10 20:49:48,649 - INFO - Round 17 of 20.
2025-02-10 20:49:49,295 - INFO - Generated 91 tokens in 0.64 seconds (141.12 tokens/sec)
2025-02-10 20:49:49,295 - INFO - Output:
Einstein's Theory of Relativity states that the speed of
light in a vacuum is simply the speed of the electrons in
that vacuum, since light has a speed. Since the speed of
light in a vacuum is equal to the speed of the electrons in
a solid, the light from this source has a speed of
approximately 1/299,792 m/s. Einstein's theory of relativity
explains this speed by a phenomenon known as the speed at
the end of time. In other words, this speed is
2025-02-10 20:49:49,295 - INFO - Round 18 of 20.
2025-02-10 20:49:49,939 - INFO - Generated 91 tokens in 0.64 seconds (141.44 tokens/sec)
2025-02-10 20:49:49,939 - INFO - Output:
Einstein's Theory of Relativity states that the speed of
light in a vacuum is simply the speed of the electrons in
that vacuum, since light has a speed. Since the speed of
light in a vacuum is equal to the speed of the electrons in
a solid, the light from this source has a speed of
approximately 1/299,792 m/s. Einstein's theory of relativity
explains this speed by a phenomenon known as the speed at
the end of time. In other words, this speed is
2025-02-10 20:49:49,939 - INFO - Round 19 of 20.
2025-02-10 20:49:50,582 - INFO - Generated 91 tokens in 0.64 seconds (141.49 tokens/sec)
2025-02-10 20:49:50,583 - INFO - Output:
Einstein's Theory of Relativity states that the speed of
light in a vacuum is simply the speed of the electrons in
that vacuum, since light has a speed. Since the speed of
light in a vacuum is equal to the speed of the electrons in
a solid, the light from this source has a speed of
approximately 1/299,792 m/s. Einstein's theory of relativity
explains this speed by a phenomenon known as the speed at
the end of time. In other words, this speed is
2025-02-10 20:49:50,583 - INFO - Round 20 of 20.
2025-02-10 20:49:51,232 - INFO - Generated 91 tokens in 0.65 seconds (140.31 tokens/sec)
2025-02-10 20:49:51,232 - INFO - Output:
Einstein's Theory of Relativity states that the speed of
light in a vacuum is simply the speed of the electrons in
that vacuum, since light has a speed. Since the speed of
light in a vacuum is equal to the speed of the electrons in
a solid, the light from this source has a speed of
approximately 1/299,792 m/s. Einstein's theory of relativity
explains this speed by a phenomenon known as the speed at
the end of time. In other words, this speed is
2025-02-10 20:49:51,232 - INFO - Run details saved to gpt2-rates-2025-02-10-20-49-51-232526-torch-compile-max-autotune-fullgraph-py313t.json.
torch.__init__: Ignoring unsupported torch.compile() with no GIL unsupported
torch._dynamo.eval_frame: Ignoring unsupported torch.compile() with no GIL unsupported
torch.__init__: Ignoring unsupported torch.compile() with no GIL unsupported
torch._dynamo.eval_frame: Ignoring unsupported torch.compile() with no GIL unsupported
real 0m20.061s
user 0m23.272s
sys 0m1.387s
Exception ignored in: <_io.BufferedWriter name=41>
BrokenPipeError: [Errno 32] Broken pipe